Lab:https://pdos.csail.mit.edu/6.828/2021/labs/cow.html
代码:https://github.com/Groupsun/xv6-riscv/tree/cow
前言
xv6的Copy-on-Write Fork实验算是从课程开始以来遇到的难度最高的一个实验了,里面有很多的坑,且代码量以及完成的时间都比其他的实验题目显著增加,因此把这个实验的过程记录下来作为参考。
预备知识
在谈这个实验之前,可以先花些时间过一下相关的预备知识作为预备,如果对这块比较熟悉的可以直接跳到实验部份。
实现虚拟内存分页的硬件
xv6基于RISC-V实现,所以首先需要理解RISC-V硬件中是如何支持分页(paging)以及虚拟内存的。关于虚拟内存相关的内容在这里不再赘述,假设读者已经有这部份的基本认知。由于xv6使用的是基于Sv39的虚拟内存系统,因此下面都是基于Sv39进行阐述(除此之外还有Sv48/Sv57等)。
实现虚拟内存的核心是虚实地址的转换,当OS启用了虚拟内存分页后,此时所有执行的指令的地址此时都不是真实的物理地址而是虚拟地址,所有指令的虚拟地址都要经过分页硬件进行转换得到物理地址才能执行,转换的过程由硬件控制,但页表的配置是由软件完成的。首先来了解硬件地址转换的过程:
在64位的机器中,所有的虚拟地址都是64位,对于Sv39来说,以最基础的4K页为准,VA(虚拟地址,下同)的组成为:
0~11bit:页内偏移
12~38bit:页表索引
39~63bit:扩展位
页内偏移对于VA以及PA(物理地址,下同)来说是一致的,扩展位也不参与分页机制。分页机制的实现在于中间这27-bit的页表索引当中。Sv39采用三级页表的分页机制,如下图所示:
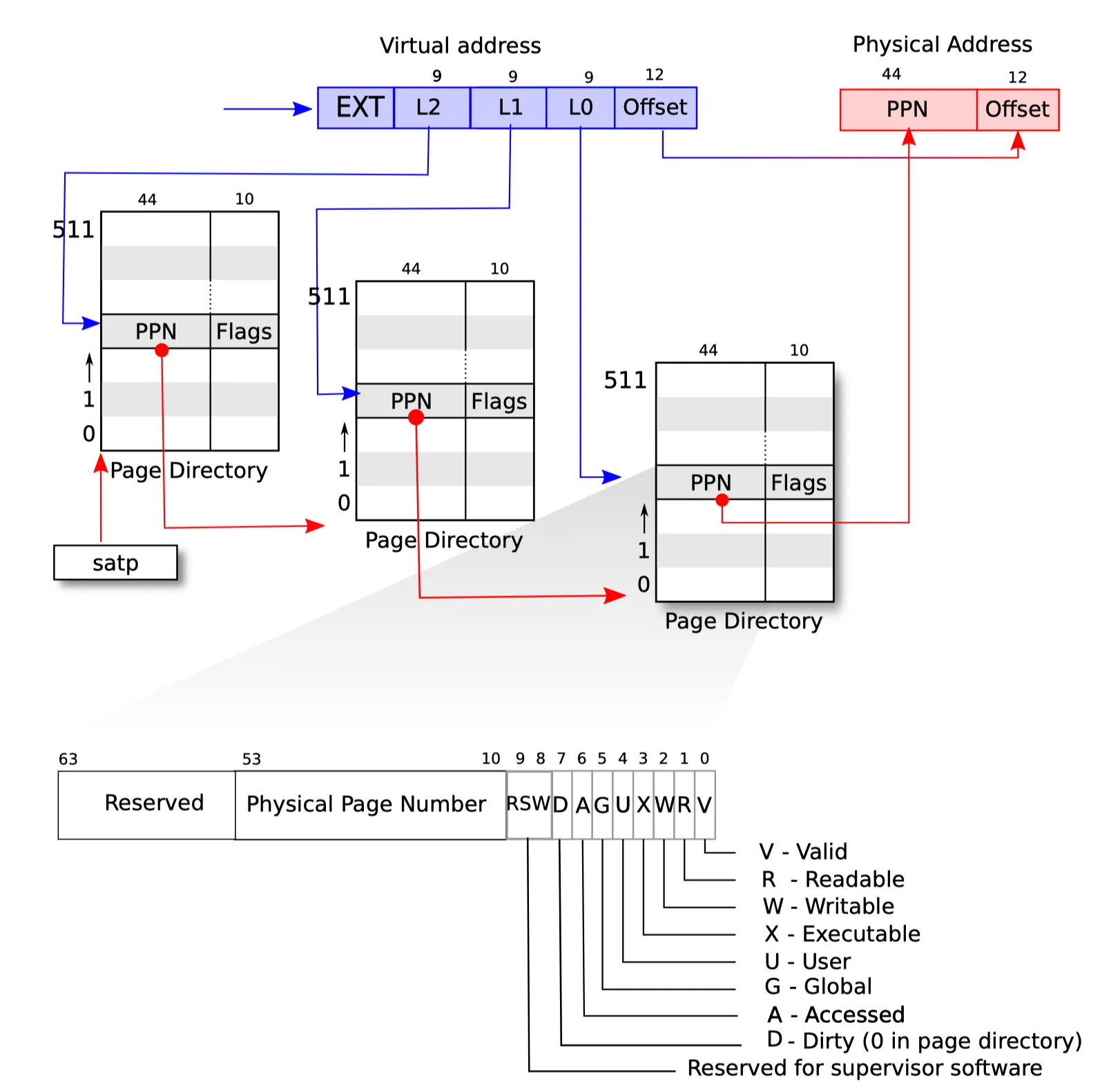
27-bit的页表索引被分割成3个9-bit,从高到低分别索引L2/L1以及L0级的页表。之所以是9-bit,是因为9-bit可以表示512个PTE(页表项),而每个PTE是64-bit(8 Byte),那么整个页表的大小是512*8=4096 Byte=4KB,刚好可以放进一个物理页当中。satp寄存器(Supervisor Address Translation and Protection Register)配置着当前根页表的物理地址页号(PPN)、地址空间标识(ASID,通常用于进程切换)以及分页模式(MODE):(64-bit satp)

PPN:根页表物理地址页号,表示当前使用的最顶级页表(Sv39是L2)的物理地址页号,也就是物理地址的第12-bit到最高bit。
ASID:地址空间标识,在进程上下文切换的时候使用。xv6没有使用这个域,因为它默认每次上下文以及特权级的切换都会用xfence刷页表。实际上进行进程切换可以使用ASID标识,也就是切换的时候修改PPN以及ASID,就可以避免刷页表的开销,因为ASID不同也会导致无法命中TLB中的PTE项
MODE:编码如下
只有当正确配置了satp寄存器之后,硬件才能启用虚拟内存以及分页管理机制。此外,上图还给出了页表项(PTE)的结构,低10-bit用于表示PTE的各项属性,包括有效位(V)、可读(R)、可写(W)、可执行(X)、用户级(U)等等,硬件在进行地址转换的时候也会同时查询页表项的属性,如果发现权限不满足,如尝试写入不可写的页、用户态下访问不具有用户级权限的页的时候,都会触发Page Fault的异常。同时,bit 8/9用于保留给软件使用,在COW的实验当中我们就需要用到。
在启用Sv39的虚拟地址硬件转换流程如下:
使用VA的L2 index作为当前stap中存储的根页表PPN的偏移量查找对应L1级页表的起始物理地址页表号
使用VA的L1 index作为L1级页表的起始物理地址页表号的偏移量查找对应L0级页表的起始物理地址页表号
使用VA的L0 index作为L0级页表的起始物理地址页表号的偏移量索引到叶节点PTE
检查PTE各项属性是否合法,若合法则将PTE的PPN拼接到VA的页内偏移得到PA,否则触发Page Fault
xv6内存管理
在了解了RISC-V硬件是怎么实现分页以及虚拟内存机制之后,我们再来看看xv6里面是怎么实现内存管理的机制的。
这里的xv6是基于xv6-labs-2021中的内容,在后续的版本中可能会有些许差别。
物理内存管理
xv6对物理内存管理的代码位于kalloc.c。xv6对物理内存的管理非常简单,使用一个单向的链表freelist来存储当前物理内存中可用的页:
struct run {
struct run *next;
};
struct {
struct spinlock lock;
struct run *freelist;
} kmem;
kinit在启动内核的时候用于初始化物理内存:
void
kinit()
{
initlock(&kmem.lock, "kmem"); // 初始化物理内存管理结构体所使用的自旋锁
freerange(end, (void*)PHYSTOP); // 初始化可用的物理内存(从kernel后的第一个地址到PHYSTOP)
}
void
freerange(void *pa_start, void *pa_end)
{
char *p;
p = (char*)PGROUNDUP((uint64)pa_start); // 起始地址对齐4K页边界
for(; p + PGSIZE <= (char*)pa_end; p += PGSIZE) // 对每个物理页执行kfree加入freelist当中
kfree(p);
}
其主要的工作为:
初始化用于保证
freelist访问原子性的自旋锁(这个非常重要,如果没有正确加锁,则会造成内存泄漏的问题,这个在接下来的COW实验中尤为重要)初始化
freelist:将kernel text/data后到PHYSTOP的可用物理内存空间进行初始化,加入
freelist当中freelist初始的表头位于kernel当中,每个空闲的物理页都会写入一个指向下一个空闲页的指针next
freerange中调用的kfree用于释放对应的物理页空间:
void
kfree(void *pa)
{
struct run *r;
if(((uint64)pa % PGSIZE) != 0 || (char*)pa < end || (uint64)pa >= PHYSTOP)
panic("kfree");
// Fill with junk to catch dangling refs.
memset(pa, 1, PGSIZE);
r = (struct run*)pa;
acquire(&kmem.lock); // 获取锁
r->next = kmem.freelist; // next指向当前表头
kmem.freelist = r; // 修改表头
release(&kmem.lock); // 释放锁
}
里面只涉及到简单的链表操作,在这里就不加赘述了。分配物理页由kalloc完成:
void *
kalloc(void)
{
struct run *r;
acquire(&kmem.lock); // 获取锁
r = kmem.freelist; // 获取freelist表头
if(r) // 若表头有效,则移动表头至链表下一项
kmem.freelist = r->next;
release(&kmem.lock); // 释放锁
if(r)
memset((char*)r, 5, PGSIZE); // fill with junk
return (void*)r;
}
同样,里面链表操作也是十分简单,这里也不再赘述了。
虚拟内存管理
xv6对虚拟内存管理的代码位于vm.c,对分页机制的管理都位于这当中。
首先是初始化内核页表,在kvminit中完成:
void
kvminit(void)
{
kernel_pagetable = kvmmake();
}
一些与分页相关会用到的宏定义:
#define PTE_V (1L << 0) // valid
#define PTE_R (1L << 1)
#define PTE_W (1L << 2)
#define PTE_X (1L << 3)
#define PTE_U (1L << 4) // 1 -> user can access
// shift a physical address to the right place for a PTE.
#define PA2PTE(pa) ((((uint64)pa) >> 12) << 10)
#define PTE2PA(pte) (((pte) >> 10) << 12)
#define PTE_FLAGS(pte) ((pte) & 0x3FF)
// extract the three 9-bit page table indices from a virtual address.
#define PXMASK 0x1FF // 9 bits
#define PXSHIFT(level) (PGSHIFT+(9*(level)))
#define PX(level, va) ((((uint64) (va)) >> PXSHIFT(level)) & PXMASK)
通过调用kvmmake来构建内核页表,并返回根页表的物理地址:
pagetable_t
kvmmake(void)
{
pagetable_t kpgtbl;
kpgtbl = (pagetable_t) kalloc();
memset(kpgtbl, 0, PGSIZE);
// uart registers
kvmmap(kpgtbl, UART0, UART0, PGSIZE, PTE_R | PTE_W);
// virtio mmio disk interface
kvmmap(kpgtbl, VIRTIO0, VIRTIO0, PGSIZE, PTE_R | PTE_W);
// PLIC
kvmmap(kpgtbl, PLIC, PLIC, 0x400000, PTE_R | PTE_W);
// map kernel text executable and read-only.
kvmmap(kpgtbl, KERNBASE, KERNBASE, (uint64)etext-KERNBASE, PTE_R | PTE_X);
// map kernel data and the physical RAM we'll make use of.
kvmmap(kpgtbl, (uint64)etext, (uint64)etext, PHYSTOP-(uint64)etext, PTE_R | PTE_W);
// map the trampoline for trap entry/exit to
// the highest virtual address in the kernel.
kvmmap(kpgtbl, TRAMPOLINE, (uint64)trampoline, PGSIZE, PTE_R | PTE_X);
// map kernel stacks
proc_mapstacks(kpgtbl);
return kpgtbl;
}
首先通过
kalloc分配一个物理页给内核根页表使用调用
kvmmap来映射UART、VIRTIO、PLIC以及kernel text/data、tramponline的地址空间UART、VIRTIO以及PLIC采用直接映射,权限为可读写kernel text(
etext是kernel text的结尾处)采用直接映射,权限为可读可执行kernel data以及余下的物理地址空间采用直接映射,权限为可读写(当启用了虚拟内存以及分页后,kernel也需要能够直接访问所有的物理内存,完成诸如
kalloc以及kfree的操作)tramponline直接映射到VA的最高位,权限为可读可执行(这是为了与用户态的处理一致,tramponline是用户态以及内核态共享的trap处理代码,可以简化在内核态以及用户态之间切换时地址处理的流程)
接下来调用
proc_mapstacks来配置所有可用进程的内核栈:
void
proc_mapstacks(pagetable_t kpgtbl) {
struct proc *p;
for(p = proc; p < &proc[NPROC]; p++) {
char *pa = kalloc();
if(pa == 0)
panic("kalloc");
uint64 va = KSTACK((int) (p - proc)); // #define KSTACK(p) (TRAMPOLINE - ((p)+1)* 2*PGSIZE)
kvmmap(kpgtbl, va, (uint64)pa, PGSIZE, PTE_R | PTE_W);
}
}
每个内核栈页上下都有一个无效的invalid page作为guard page来防止恶意程序在用户态尝试通过栈溢出的攻击方式来获取内核栈的数据。这里给出xv6的内核态地址空间的示意图:
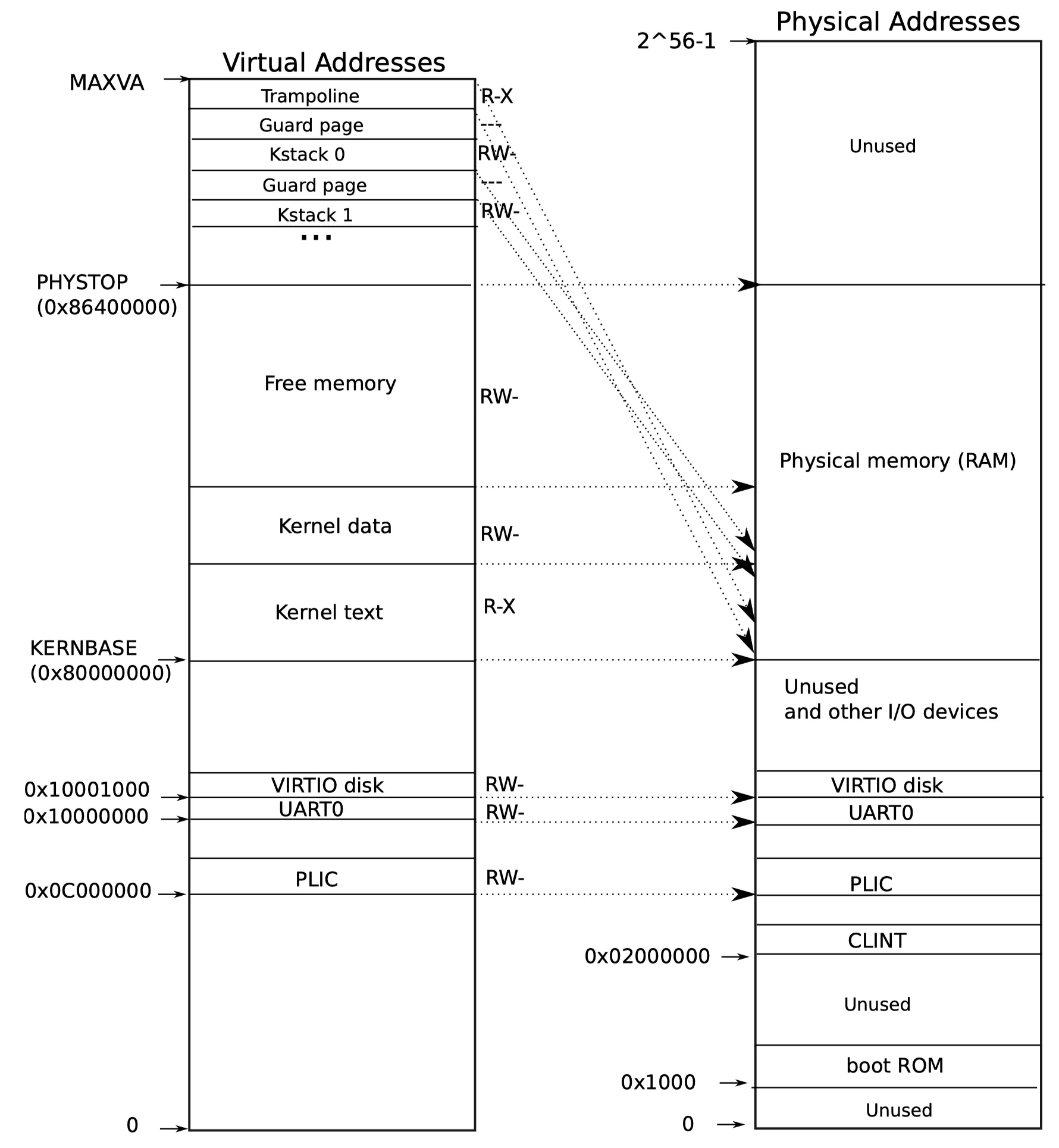
再来看初始化内核页表的关键函数kvmmap,它实际上就是调用了mappages,因为此时还没有配satp,所以并不需要xfence:
void
kvmmap(pagetable_t kpgtbl, uint64 va, uint64 pa, uint64 sz, int perm)
{
if(mappages(kpgtbl, va, sz, pa, perm) != 0)
panic("kvmmap");
}
mappages(pagetable_t pagetable, uint64 va, uint64 size, uint64 pa, int perm)
{
uint64 a, last;
pte_t *pte;
if(size == 0)
panic("mappages: size");
a = PGROUNDDOWN(va); // 获取向下4K页对齐的VA
last = PGROUNDDOWN(va + size - 1); // 获取向下4K页对齐的最后一个页的地址
for(;;){
if((pte = walk(pagetable, a, 1)) == 0) // 遍历页表,创建对应的非叶节点页表映射,返回叶节点PTE地址
return -1;
if(*pte & PTE_V) // 由于是初始化,不可能也不应该有已存在的内核页表映射
panic("mappages: remap");
*pte = PA2PTE(pa) | perm | PTE_V; // 创建映射,配置PTE属性
if(a == last)
break;
a += PGSIZE;
pa += PGSIZE;
}
return 0;
}
walk函数从根页表(L2)开始逐级往下遍历页表,当alloc为1时,若中间的非叶节点页表不存在,则会进行创建,最后返回叶节点PTE的地址:
pte_t *
walk(pagetable_t pagetable, uint64 va, int alloc)
{
if(va >= MAXVA)
panic("walk");
for(int level = 2; level > 0; level--) { // 逐级往下遍历页表
pte_t *pte = &pagetable[PX(level, va)]; // 获取当前页表对应index的PTE entry;
if(*pte & PTE_V) {
pagetable = (pagetable_t)PTE2PA(*pte); // 若entry有效则直接切换到下一级页表
} else {
if(!alloc || (pagetable = (pde_t*)kalloc()) == 0) // 若alloc==0则直接return 0
return 0; // 若alloc==1则分配一个物理页给当前index对应的PTE entry
memset(pagetable, 0, PGSIZE);
*pte = PA2PTE(pagetable) | PTE_V; // 写入PA以及valid属性
}
}
return &pagetable[PX(0, va)];
}
至此,内核页表的构建完成。接下来每个CPU core的内核都会调用kvminithart来初始化satp,启用虚拟内存分页并执行sfence.vma刷所有TLB:
// flush the TLB.
static inline void
sfence_vma()
{
// the zero, zero means flush all TLB entries.
asm volatile("sfence.vma zero, zero");
}
void
kvminithart()
{
w_satp(MAKE_SATP(kernel_pagetable)); // #define MAKE_SATP(pagetable) (SATP_SV39 | (((uint64)pagetable) >> 12))
sfence_vma();
}
用户态进程页表管理
当使用fork创建一个新的进程时,首先会创建一个只带有trampoline页以及进程的trapframe页的页表给新创建的进程:
// create an empty user page table.
// returns 0 if out of memory.
pagetable_t
uvmcreate()
{
pagetable_t pagetable;
pagetable = (pagetable_t) kalloc();
if(pagetable == 0)
return 0;
memset(pagetable, 0, PGSIZE);
return pagetable;
}
// Create a user page table for a given process,
// with no user memory, but with trampoline pages.
pagetable_t
proc_pagetable(struct proc *p)
{
pagetable_t pagetable;
// An empty page table.
pagetable = uvmcreate(); // 创建仅包含根页表页的空页表
if(pagetable == 0)
return 0;
// map the trampoline code (for system call return)
// at the highest user virtual address.
// only the supervisor uses it, on the way
// to/from user space, so not PTE_U.
if(mappages(pagetable, TRAMPOLINE, PGSIZE,
(uint64)trampoline, PTE_R | PTE_X) < 0){
uvmfree(pagetable, 0);
return 0;
}
// map the trapframe just below TRAMPOLINE, for trampoline.S.
if(mappages(pagetable, TRAPFRAME, PGSIZE,
(uint64)(p->trapframe), PTE_R | PTE_W) < 0){
uvmunmap(pagetable, TRAMPOLINE, 1, 0);
uvmfree(pagetable, 0);
return 0;
}
return pagetable;
}
在没有实现COW fork之前,fork会为将父进程所有的用户内存都拷贝到子进程当中:
int
fork(void)
{
// ...
// Copy user memory from parent to child.
if(uvmcopy(p->pagetable, np->pagetable, p->sz) < 0){
freeproc(np);
release(&np->lock);
return -1;
}
// ...
}
其调用了uvmcopy函数,也是我们接下来要在COW fork实验中重点修改的函数:
// Given a parent process's page table, copy
// its memory into a child's page table.
// Copies both the page table and the
// physical memory.
// returns 0 on success, -1 on failure.
// frees any allocated pages on failure.
int
uvmcopy(pagetable_t old, pagetable_t new, uint64 sz)
{
pte_t *pte;
uint64 pa, i;
uint flags;
char *mem;
for(i = 0; i < sz; i += PGSIZE){ // 从va=0开始拷贝直至父进程sz为止
if((pte = walk(old, i, 0)) == 0) // 遍历页表,获取当前VA对应的叶节点PTE
panic("uvmcopy: pte should exist");
if((*pte & PTE_V) == 0)
panic("uvmcopy: page not present");
pa = PTE2PA(*pte); // 获取当前父进程VA页对应的PA
flags = PTE_FLAGS(*pte); // 获取当前父进程VA页页属性
if((mem = kalloc()) == 0) // 为子进程分配一个物理页
goto err;
memmove(mem, (char*)pa, PGSIZE); // 拷贝当前父进程VA页数据到子进程新分配的物理页当中
if(mappages(new, i, PGSIZE, (uint64)mem, flags) != 0){ // 将新分配的页映射到子进程的页表中
kfree(mem);
goto err;
}
}
return 0;
err:
uvmunmap(new, 0, i / PGSIZE, 1); // 只要中途出现错误,则释放掉之前已经映射的页表项
return -1;
}
// Remove npages of mappings starting from va. va must be
// page-aligned. The mappings must exist.
// Optionally free the physical memory.
void
uvmunmap(pagetable_t pagetable, uint64 va, uint64 npages, int do_free)
{
uint64 a;
pte_t *pte;
if((va % PGSIZE) != 0) // 要释放的va对应的映射,va必须要对齐4K页边界
panic("uvmunmap: not aligned");
for(a = va; a < va + npages*PGSIZE; a += PGSIZE){
if((pte = walk(pagetable, a, 0)) == 0) // 获取叶节点PTE
panic("uvmunmap: walk");
if((*pte & PTE_V) == 0)
panic("uvmunmap: not mapped");
if(PTE_FLAGS(*pte) == PTE_V)
panic("uvmunmap: not a leaf");
if(do_free){ // 若需要释放对应的物理页,则调用kfree
uint64 pa = PTE2PA(*pte);
kfree((void*)pa);
}
*pte = 0; // 删除对应关系
}
}
这里可以看到虚拟地址是从0开始往上增加的,这是由于:
xv6的Makefile脚本中指定了所有用户程序的代码段(包括initcode)都是从VA==0开始的
# ... existing code ... _%: %.o $(ULIB) $(LD) $(LDFLAGS) -N -e main -Ttext 0 -o $@ $^ $(OBJDUMP) -S $@ > $*.asm $(OBJDUMP) -t $@ | sed '1,/SYMBOL TABLE/d; s/ .* / /; /^$$/d' > $*.sym # ... existing code ...创建第一个进程的uvminit函数中也可以看到,第一个进程的初始代码也是从VA==0开始的:
void uvminit(pagetable_t pagetable, uchar *src, uint sz) { // ... existing code ... mappages(pagetable, 0, PGSIZE, (uint64)mem, PTE_W|PTE_R|PTE_X|PTE_U); // ... existing code ... }
当进程需要申请更多的用户内存的时候(执行exec或者sbrk),则会调用uvmalloc来为进程申请物理内存以及映射进用户页表,如果中间发生错误则会调用uvmdealloc来删除新分配物理页的页表映射:
uint64
uvmalloc(pagetable_t pagetable, uint64 oldsz, uint64 newsz)
{
char *mem;
uint64 a;
if(newsz < oldsz)
return oldsz;
oldsz = PGROUNDUP(oldsz); // 获取当前进程VA空间的最后一个地址对应的下一个页
for(a = oldsz; a < newsz; a += PGSIZE){
mem = kalloc(); // 分配物理页
if(mem == 0){
uvmdealloc(pagetable, a, oldsz);
return 0;
}
memset(mem, 0, PGSIZE);
if(mappages(pagetable, a, PGSIZE, (uint64)mem, PTE_W|PTE_X|PTE_R|PTE_U) != 0){ // 映射进进程页表
kfree(mem);
uvmdealloc(pagetable, a, oldsz);
return 0;
}
}
return newsz;
}
// 删除页表映射,需要注意的是这里不会释放物理页
uint64
uvmdealloc(pagetable_t pagetable, uint64 oldsz, uint64 newsz)
{
if(newsz >= oldsz)
return oldsz;
if(PGROUNDUP(newsz) < PGROUNDUP(oldsz)){
int npages = (PGROUNDUP(oldsz) - PGROUNDUP(newsz)) / PGSIZE;
uvmunmap(pagetable, PGROUNDUP(newsz), npages, 1);
}
return newsz;
}
Lab: Copy-on-Write Fork
概述
在了解完预备知识后,可以正式开始COW Fork实验了。上面提到过,当前xv6中,每当fork一个进程时,内核会简单的将整个父进程的用户内存空间都拷贝一份到子进程当中,这虽然是一个很简单的实现,但是效率很低下:
如果父进程的用户内存非常大,那么完整拷贝将会是非常耗时的工作
大部分时候,拷贝整个父进程的用户内存空间都是没用的,这是因为大部分时候fork之后都会调用exec加载新的用户程序执行,这时候原先的父进程的用户内存基本无用而被丢弃掉
COW Fork就是为了解决上述的问题引入的一个feature。COW fork只会为子进程创建一份父进程页表的拷贝,而非拷贝所有的父进程用户内存空间。同时,COW fork会将清除掉父子进程的所有子节点PTE的可写属性,那么当父进程或子进程尝试去写入某个页的时候就会触发page fault(准确来说是store page fault)陷入内核,而内核将会特定这种场景并真正为父/子进程分配一个新的物理页并将数据拷贝进去,最后更新页表映射并设置为可写。
思路与HINT
实验描述中提供了一些基本的思路以及提示:
修改
uvmcopy,将父进程的页表也映射到子进程当中,而不是为子进程逐个分配新的物理页,并清除掉父子进程所有叶节点PTE的可写属性修改
usertap,现在需要store page fault的handler,在其中检查发生store page fault的页是否为COW页,如果是的话就通过kalloc为其分配新的物理页,并拷贝数据进去,最后将新分配的物理页映射到页表中需要保证每个物理页只有在最后一个映射到它的PTE被释放了的时候才能真正的释放,这里可以通过一个追踪所有物理页的reference count数组来实现:
当一个物理页使用
kalloc分配的时候,设置其reference count为1当
fork导致一个子进程共享该页的时候,将其reference count递增kfree只会真正释放reference count为0的物理页数组的大小可以是固定的(xv6的可用物理内存大小很小),并使用物理页号来索引(除以4096)
RISC-V中PTE为软件预留了bit8-9使用,可以使用该bit来特定作为COW使用的页
如果发生了COW page faults且没有空闲的物理内存了,这个进程应该被kill掉
实现
物理内存页引用计数管理
首先考虑实现物理内存页的reference count管理,这里直接使用一个固定大小的数组来实现:
// kalloc.c
// ...
extern char end[]; // first address after kernel.
// defined by kernel.ld.
// reference count for each physical page and its lock
int refcount[PHYPAGES]; // PHYPAGES = ((PHYSTOP - KERNBASE) / PGSIZE)
struct spinlock refcount_lock; // 访问refcount数组时使用的自旋锁
// ...
这里出现第一个容易出问题的点:那就是访问这个refcount数组时需要加锁以进行原子操作,否则会因为进程间切换导致的竞争最终导致内存泄漏。
在kinit中也需要初始化refcount_lock自旋锁:
void
kinit()
{
initlock(&kmem.lock, "kmem");
initlock(&refcount_lock, "refcount");
freerange(end, (void*)PHYSTOP);
}
接下来修改kfree以及kalloc函数。kfree函数中在真正释放物理页进freelist前需要检查对应的refcount是否为0,否则仅递减对应的refcount并返回。这里需要留意访问refcount需要获取锁:
void
kfree(void *pa)
{
struct run *r;
int refcount_val;
if(((uint64)pa % PGSIZE) != 0 || (char*)pa < end || (uint64)pa >= PHYSTOP)
panic("kfree");
// if the page is still in use by other processes, do not free it
acquire(&refcount_lock);
refcount[REFIDX((uint64)pa)]--; // decrement reference count
refcount_val = refcount[REFIDX((uint64)pa)]; // #define PHYPAGES ((PHYSTOP - KERNBASE) / PGSIZE)
release(&refcount_lock);
if (refcount_val > 0) // page is still in use
return;
// Fill with junk to catch dangling refs.
memset(pa, 1, PGSIZE);
r = (struct run*)pa;
acquire(&kmem.lock);
r->next = kmem.freelist;
kmem.freelist = r;
release(&kmem.lock);
}
这里还有一个需要注意的点,就是使用PA索引refcount的时候需要使用((PA - KERNBASE) / PGSIZE)的方式去索引,与数组大小对齐,否则也会导致内存泄漏的问题。
kalloc中需要在分配物理页的时候置对应的refcount为1;同样,访问refcount需要先获取锁:
void *
kalloc(void)
{
struct run *r;
acquire(&kmem.lock);
r = kmem.freelist;
if(r) {
kmem.freelist = r->next;
acquire(&refcount_lock);
refcount[REFIDX((uint64)r)] = 1; // 新分配的物理页refcount置为1
release(&refcount_lock);
}
release(&kmem.lock);
if(r)
memset((char*)r, 5, PGSIZE); // fill with junk
return (void*)r;
}
更新uvmcopy实现
接下来更新当fork子进程时调用uvmcopy的实现。在新的实现中,uvmcopy将不再拷贝整个父进程用户内存空间,而是仅拷贝父进程页表,并将父子进程所有原来是可写权限的页表属性改为不可写,并标记上为COW页(使用PTE_COW表示PTE的第8位),这是因为原来本就不可写的页不应该在之后的handler中设置为可写,这不符合意图。然后将对应的物理页的refcount递增:
// vm.c
int
uvmcopy(pagetable_t old, pagetable_t new, uint64 sz)
{
pte_t *pte;
uint64 pa, i;
uint flags;
//char *mem;
int writable;
for(i = 0; i < sz; i += PGSIZE){
if((pte = walk(old, i, 0)) == 0)
panic("uvmcopy: pte should exist");
if((*pte & PTE_V) == 0)
panic("uvmcopy: page not present");
writable = 0;
pa = PTE2PA(*pte);
flags = PTE_FLAGS(*pte);
// set COW bit and clear write bit if the page is writable
// otherwise, no need to set COW bit and clear write bit
if (flags & PTE_W) {
flags = (flags | PTE_COW) & ~PTE_W; // #define PTE_COW (1L << 8)
writable = 1;
}
//if((mem = kalloc()) == 0)
// goto err;
//memmove(mem, (char*)pa, PGSIZE);
if(mappages(new, i, PGSIZE, pa, flags) != 0){
//kfree(mem);
goto err;
}
if (writable)
*pte = (*pte | PTE_COW) & ~PTE_W;
acquire(&refcount_lock);
refcount[REFIDX(pa)]++;
release(&refcount_lock);
}
return 0;
err:
uvmunmap(new, 0, i / PGSIZE, 1);
return -1;
}
为store page fault添加handler
接下来我们需要在usertrap中为store page fault添加handler来识别对COW page进行写入的场景。当发生store page fault时,scause的值为0xF,并会将发生store page fault的VA写入到stval当中(参见RISC-V privilege spec)。首先我们需要对发生store page fault的页以及VA进行严格的检查,包括:
VA是否≥MAXVA
PTE是否有效
PTE是否是COW页
只要任意一个条件不符合,都属于非正常的page fault,需要报错并kill掉进程。若检查通过,则调用cow_handler来进行处理。
cow_handler为发生page fault的页分配一个新的物理页,并将数据拷贝进去。接下来释放掉页表中原有的映射,并将新分配的物理页映射进去,并设置上可读且清楚掉COW属性:
// trap.c
void
usertrap(void){
// ...
} else if(r_scause() == 15){
// store page fault
// if the page is marked as COW page, allocate a new page and copy the content
// and install it into the page table
// otherwise, kill the process
uint64 va = r_stval();
if (va >= MAXVA)
goto err;
pte_t *pte = walk(p->pagetable, va, 0);
if (!pte || pte == 0 || (*pte & PTE_V) == 0 || (*pte & PTE_COW) == 0)
goto err;
if (cow_handler(p->pagetable, va, PTE2PA(*pte), PTE_FLAGS(*pte)) == 0)
goto err;
}
// ...
}
char *
cow_handler(pagetable_t pagetable, uint64 va, uint64 old_pa, uint flags)
{
char *mem;
// allocate a new page
if ((mem = kalloc()) == 0)
return 0;
memmove(mem, (char *)old_pa, PGSIZE);
// unmap the old page, free the physical memory
// it would call kfree() so the reference count of the old page is decremented
uvmunmap(pagetable, PGROUNDDOWN(va), 1, 1);
// install the new page into the page table
if (mappages(pagetable, PGROUNDDOWN(va), PGSIZE, (uint64)mem, (flags | PTE_W) & ~PTE_COW) != 0)
return 0;
return mem;
}
更新copyout实现
在实现COW Fork之后,还有一个地方需要更新实现,就是从内核中拷贝数据到用户进程空间的时候,由于设计到对用户进程空间的写入,因此也需要进行类似的处理,这里直接复用cow_handler来处理:
int
copyout(pagetable_t pagetable, uint64 dstva, char *src, uint64 len)
{
uint64 n, va0, pa0;
pte_t *pte;
struct proc *p = myproc();
uint flags;
while(len > 0){
va0 = PGROUNDDOWN(dstva);
pa0 = walkaddr(pagetable, va0);
if (pa0 == 0)
return -1;
pte = walk(pagetable, va0, 0);
if (*pte == 0)
p->killed = 1;
flags = PTE_FLAGS(*pte);
// check if the page is COW page
if (va0 < p->sz && (*pte & PTE_COW) && (*pte & PTE_V)) {
// allocate a new page
// reuse the cow_handler
if((pa0 = (uint64)cow_handler(pagetable, va0, pa0, flags)) == 0)
p->killed = 1;
}
n = PGSIZE - (dstva - va0);
if(n > len)
n = len;
memmove((void *)(pa0 + (dstva - va0)), src, n);
len -= n;
src += n;
dstva = va0 + PGSIZE;
}
return 0;
}
至此,整个COW Fork feature的实现完成,完整的代码可以在github仓库上查看。
优化
在完成实验后,我发现当前的实现其实有一个可以优化的点:那就是当前实现,在COW页的reference为1的时候,发生store page fault还会重新分配一个新的物理页,这个实际上是冗余的,此时只需要更新该PTE的属性即可。