论文原文:
概述
分支预测算法在现代的超标量处理器中扮演着至关重要的角色,其一般在处理器中的BPU(Branch Prediction Units)当中实现。在大多数的设计当中,传统意义上的BPU通过已经退休的分支指令结果来训练静态的预测模型,并利用其预测接下来取到的分支指令。从另一个角度来说,大多数的BPU的训练以及推理的过程都是“在线”(online)完成的,也就是在处理器运行时同时进行。
虽然SOTA的分支预测器已经可以达到接近于完美的预测准确率,但是如果能够使分支预测器可以覆盖或者纠正其余的错误预测的分支指令,那么处理器整体的吞吐率就能更上一层楼。如下图所示,如果没有更好的分支预测算法,而使用当前SOTA的TAGE-SC-L分支预测算法,单纯等比例的放大Intel Skylake各个流水线级中的资源所带来的IPC性能回报会急剧减少:
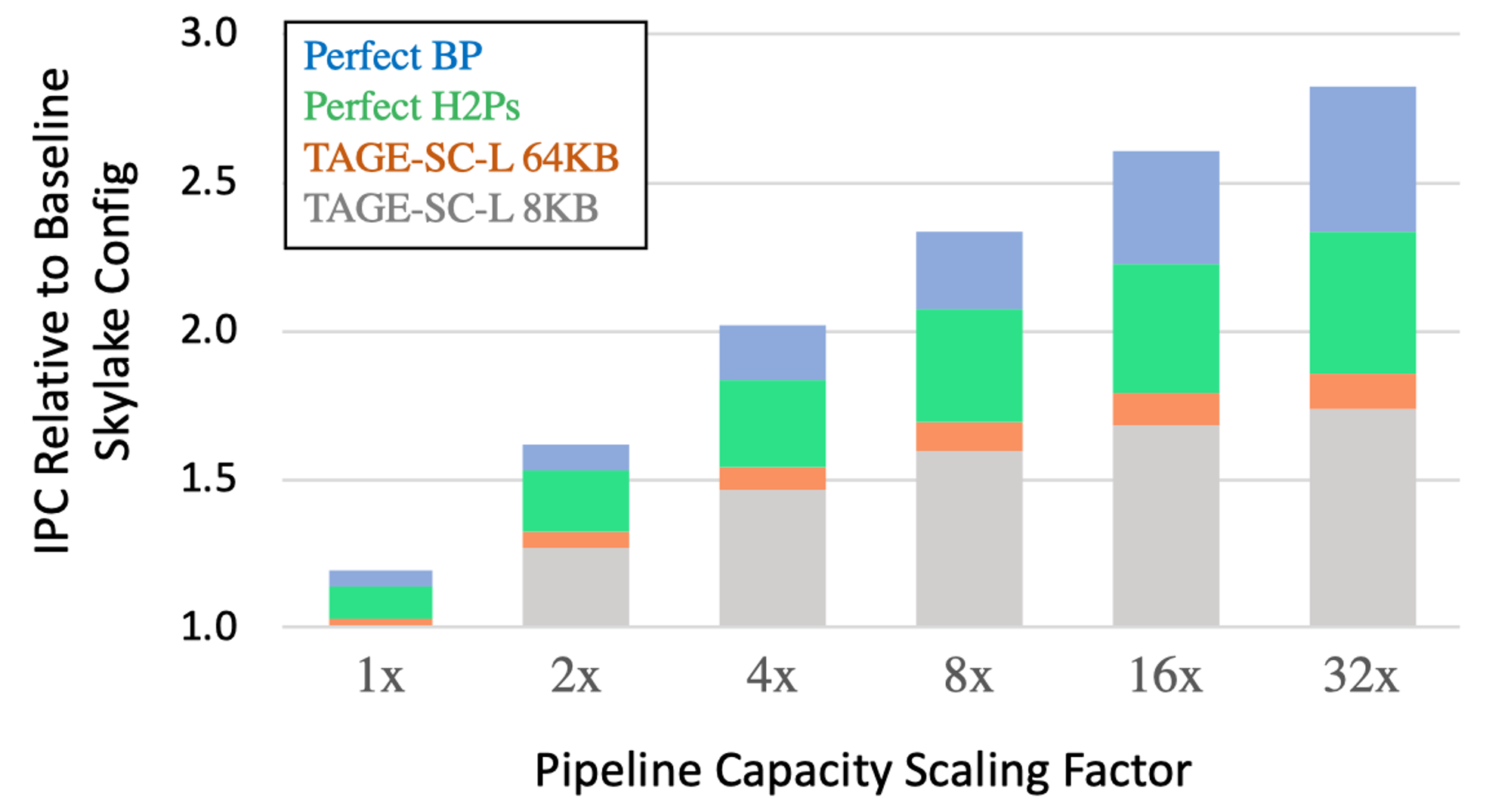
本文会深入分析造成余下分支指令预测错误的原因,并提出一些新的分支预测算法研究方向来解决这些问题。造成当前SOTA的分支预测器无法准确预测的主要有两种分支指令:
系统性的难以预测的分支指令(hard-to-predict, H2P branches)
在数以千万计的指令中动态执行很少次数的分支指令(rare branches)
这些分支指令在恶化IPC的同时,还会浪费大量的BPU存储空间,同时呈现出与当前已知的分支预测算法在短期训练信息中反常的行为,亦即会干扰已经成功捕捉的其他分支历史行为信息。我们提出通过部署机器学习的模型来捕捉并提高这些H2P的模式以及预测准确性(比如使用低精度的卷积神经网络)。
现代流行的分支预测算法分类
现代超标量微处理器中的BPU所实现的分支预测算法依赖于以下3种ground truth来进行训练以及预测:
全局分支历史(global branch history)
各个分支自身的分支历史(local history)
路径历史(path history,最近执行的分支指令的PC信息)
而现代流行的分支预测算法所训练的模型种类可以分为以下4种:
局部模式匹配(Partial Pattern Matching,PPM),通过哈希的分支历史信息来匹配变长的分支历史执行模式以返回最长匹配的预测结果。典型代表是TAGE。
感知器预测器(Perceptron Predictors),可以弥补PPM中精确模式匹配的缺点:在不具有分支历史模式相关性的分支指令预测精度低的问题。感知预测器通过训练记录分支指令自身预测信息权重的神经元(更依赖于local information),并在预测时计算各个神经元的权重来得到预测结果。典型代表是TAGE-SC-L变体中的SC。
针对特定领域的模型(Domain-Specific Models),用于捕捉特定场景的算法模型,典型代表是TAGE-SC-L变体中的L,IMLI(Inner-Most Loop Iteration counter)中用于捕捉多级嵌套循环中分支指令相关性的预测器,以及存储/加载预测器,用于追踪分支指令依赖数据相关性。
混合模型(Ensemble Models),通过训练多种不同模型来得到最终的单一预测,如TAGE-SC-L。
错误预测分支指令的行为分析
SPECint 2017中的H2P分支指令
首先给出H2P分支指令的具体定义:
在TAGE-SC-L 8KB配置的分支预测算法下低于99%的准确率
至少执行了15000次
在单个切片中错误预测了至少1000次
下表展示了除603.gcc_s以外的SPECint 2017 Benchmark的执行统计信息。
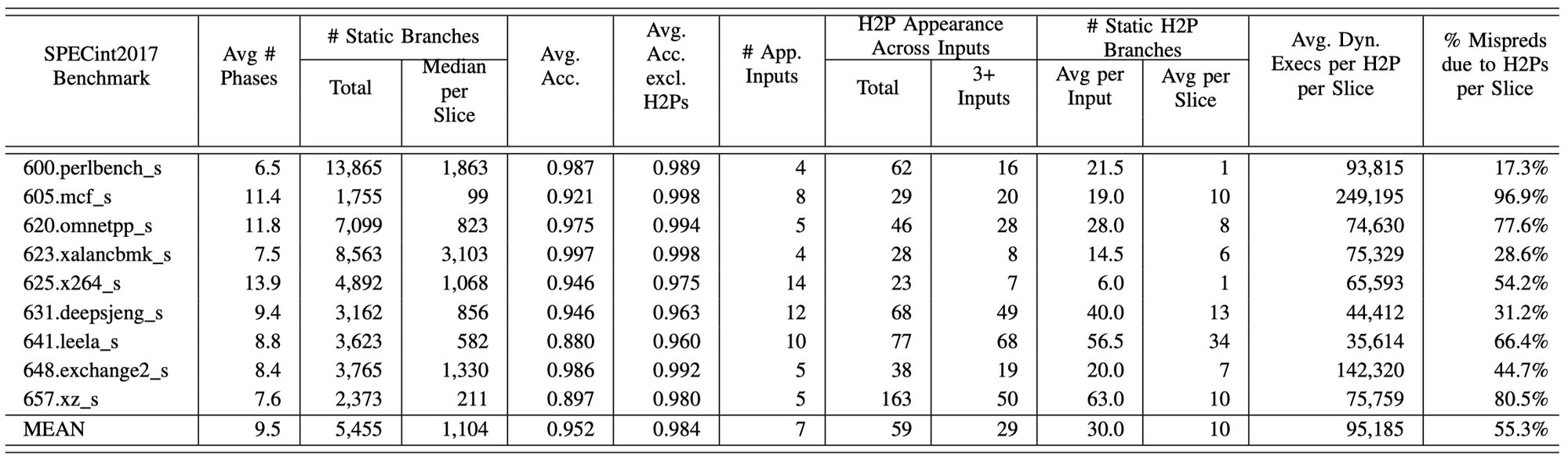
可以发现:
只存在少数的H2Ps在测试执行过程中不断的产生错误预测,平均来说,每个测试有29个此种类型的H2Ps存在于≥3个输入的负载当中。
对于所有类型的测试负载,每3000万个指令切片中55.3%的错误预测仅仅由平均10个H2Ps所导致。
下图给出了对于每个测试中由于H2P造成的错误预测的累计比例,可以发现最靠前的5个H2Ps达到了平均37%的动态错误预测率,这些H2Ps也被称为”heavy-hitters“。
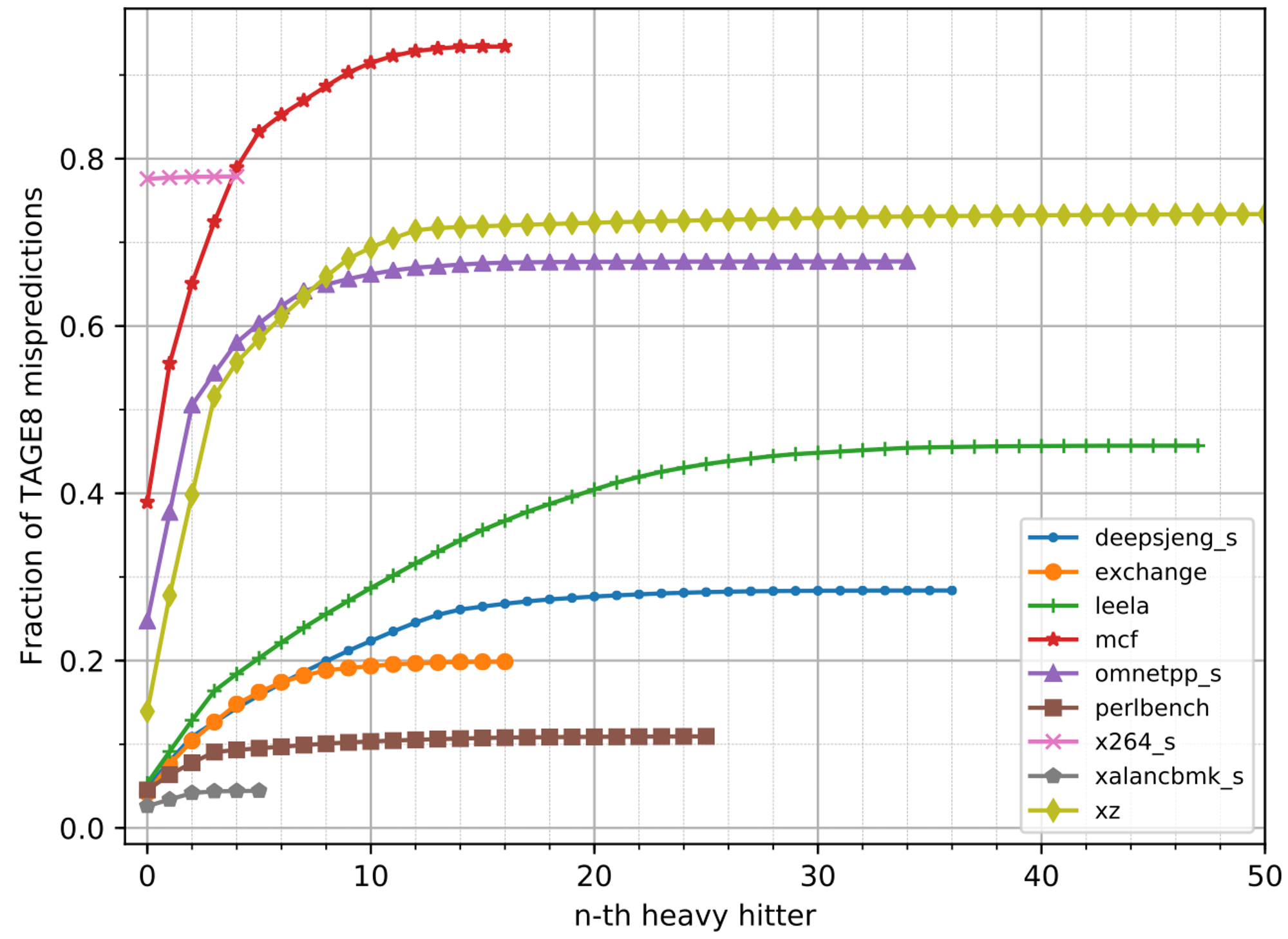
综合上述的分析,我们可以得到结论:仅仅少数几个H2P静态分支指令就可以造成不合比例/非预期的大量动态分支预测错误。
在LCF中较少执行分支指令的追踪
603.gcc_s是一个有点特殊的LCF(large code footprint)测试集,它具有大量的较少执行的分支指令,但是它们却造成了大量的分支预测错误。
下表给出了TAGE-SC-L 8KB分支预测器在各种LCF应用下的统计信息:
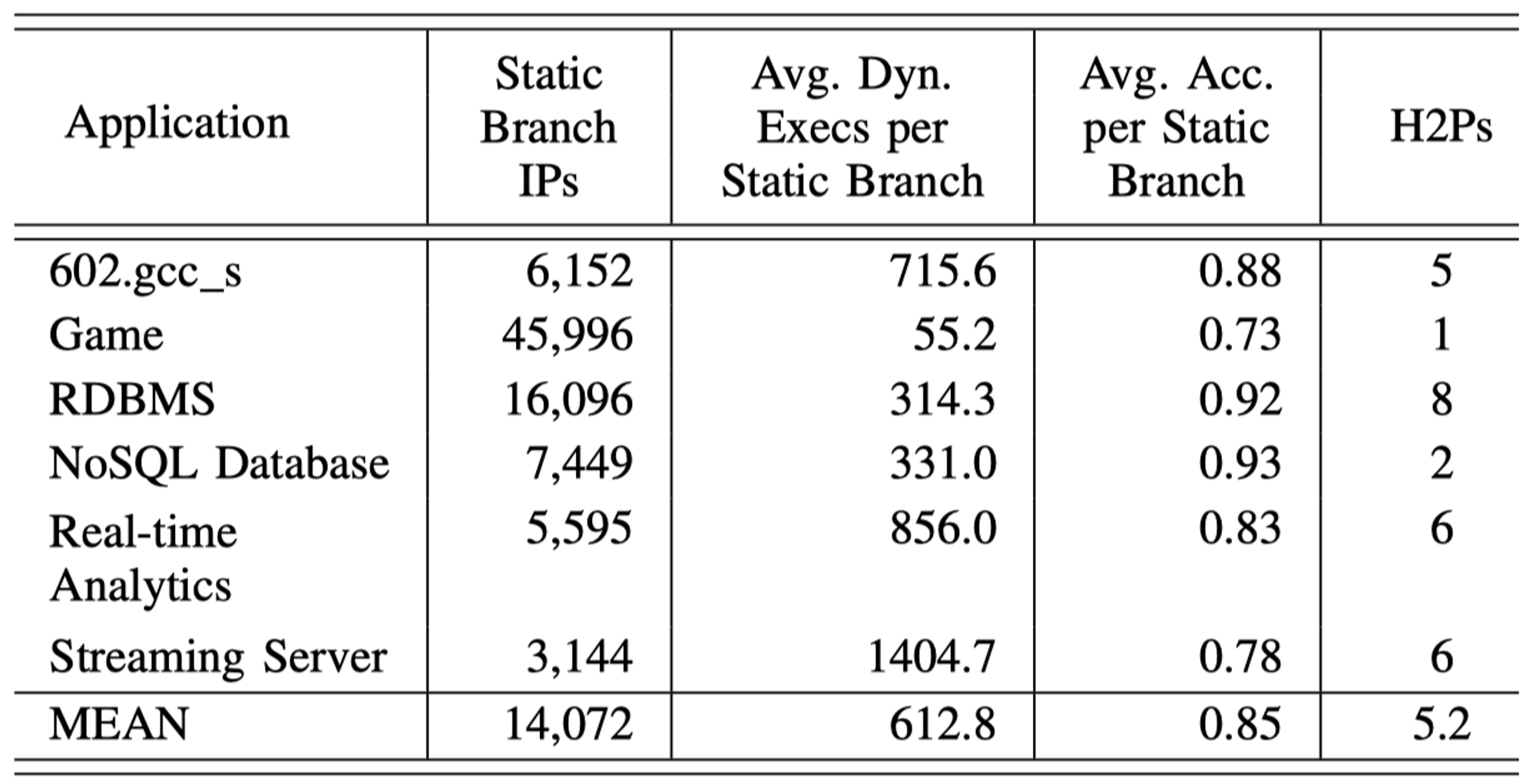
可以发现:
TAGE-SC-L 8KB的分支预测器在这些LCF应用下的准确率(0.85)远低于SPECint 2017测试集(0.952)
对于每个LCF应用下的大量静态分支指令(平均14072条),它们动态执行次数却很少(平均612.8次)
下图给出了这些静态分支指令各项指标的分布情况:
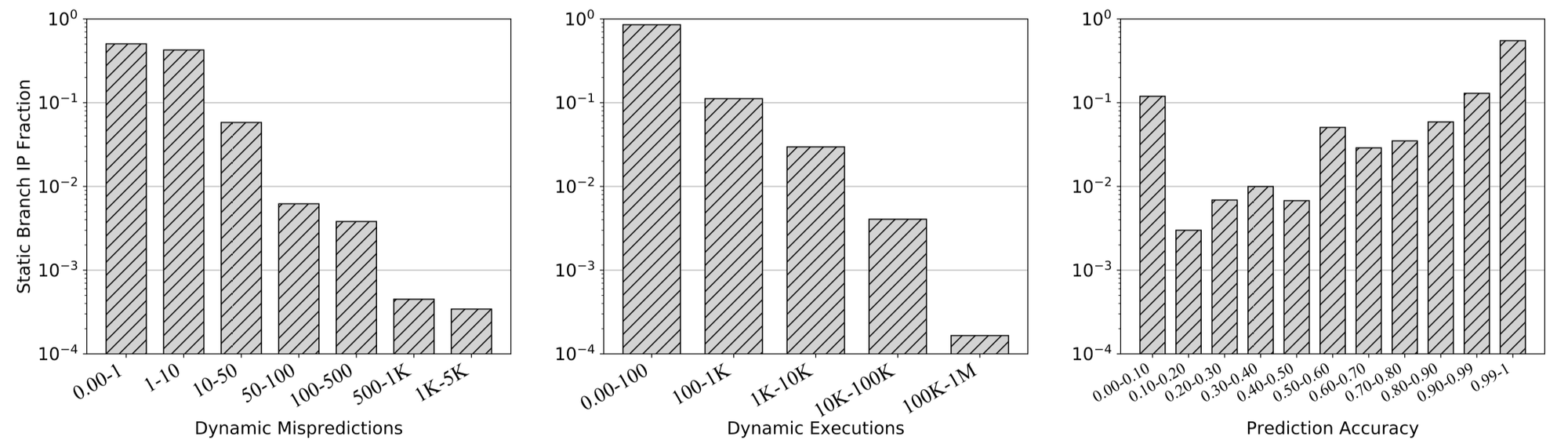
可以发现:
动态执行次数的分布(中位数)偏左,即动态执行次数偏少,85%的静态分支指令执行少于100次
动态执行预测错误次数的分布偏左,大量的静态分支预测都具有极高的准确性
预测准确率的分布偏右,55%的静态分支预测准确率都≥0.99;然而,12%的静态分支准确率却≤0.10
下图a给出了每个静态分支指令的执行次数以及准确率的分布图,图b给出了静态分支指令依据执行次数的标准偏差:
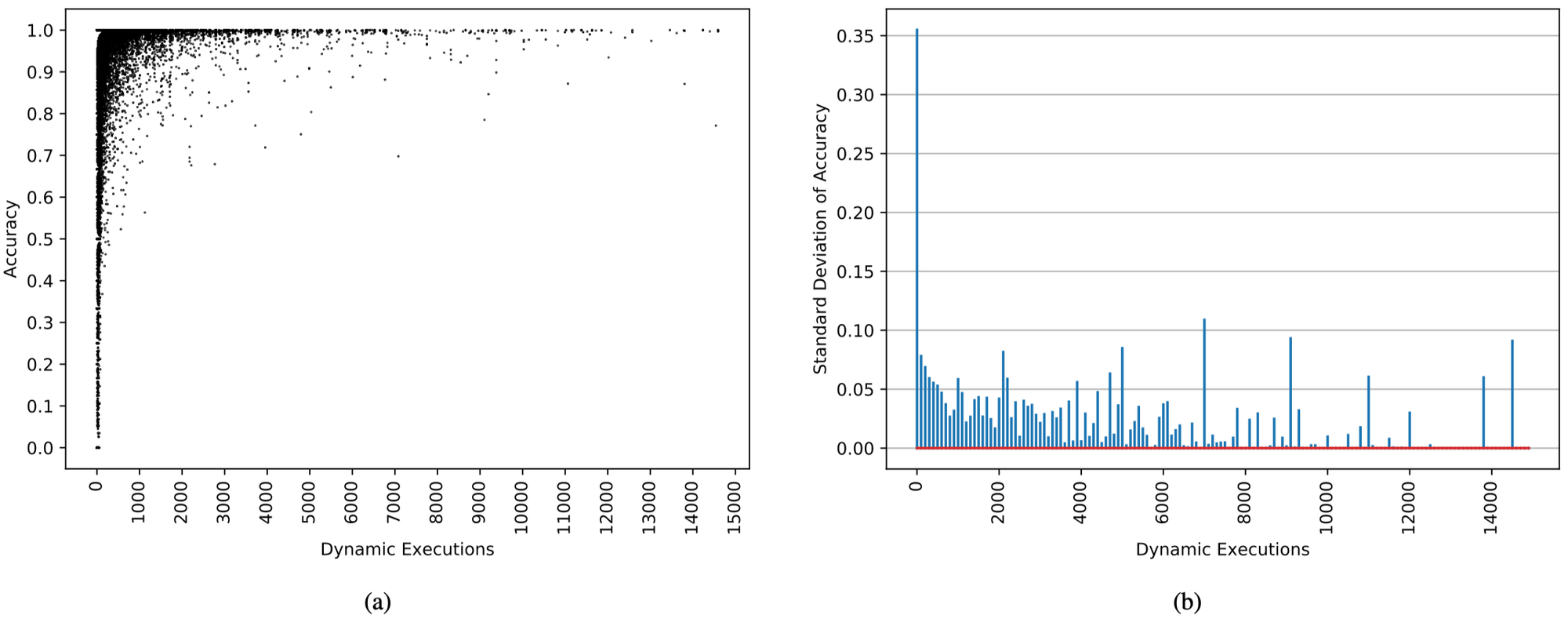
可以发现:
具有低动态执行次数的静态分支指令的预测准确率分布很广。这是符合预期的,因为这些指令的历史信息非常少,导致其预测的信息度很低
对于只有0~100次执行次数的静态分支指令来说,其预测准确率的标准偏差非常大(0.35),也进一步说明了上一点。而100~200次执行次数的静态分支指令其预测准确率的标准偏差就骤减到了0.08
综合上面的分析,我们可以得到结论:LCF应用中存在大量的执行次数很少的静态分支指令,且预测准确度分布非常广,但由于其执行次数太少,无法归类为H2P分支指令。
等比例放大CPU流水级资源对误预测率的影响
通过上述两节的分析,可以发现H2Ps以及执行次数很少的静态分支指令在等比例放大CPU流水级资源的时候,其对性能的影响也并不相同。对于SCL(small code footprint)的应用来说,H2Ps更为重要,也就是说,如果可以解决H2Ps的预测准确度低的问题,SCL应用的性能会得到极大的提升。然而,对于LCF应用来说,执行次数很少的静态分支指令则扮演者更为重要的角色,如下图所示:
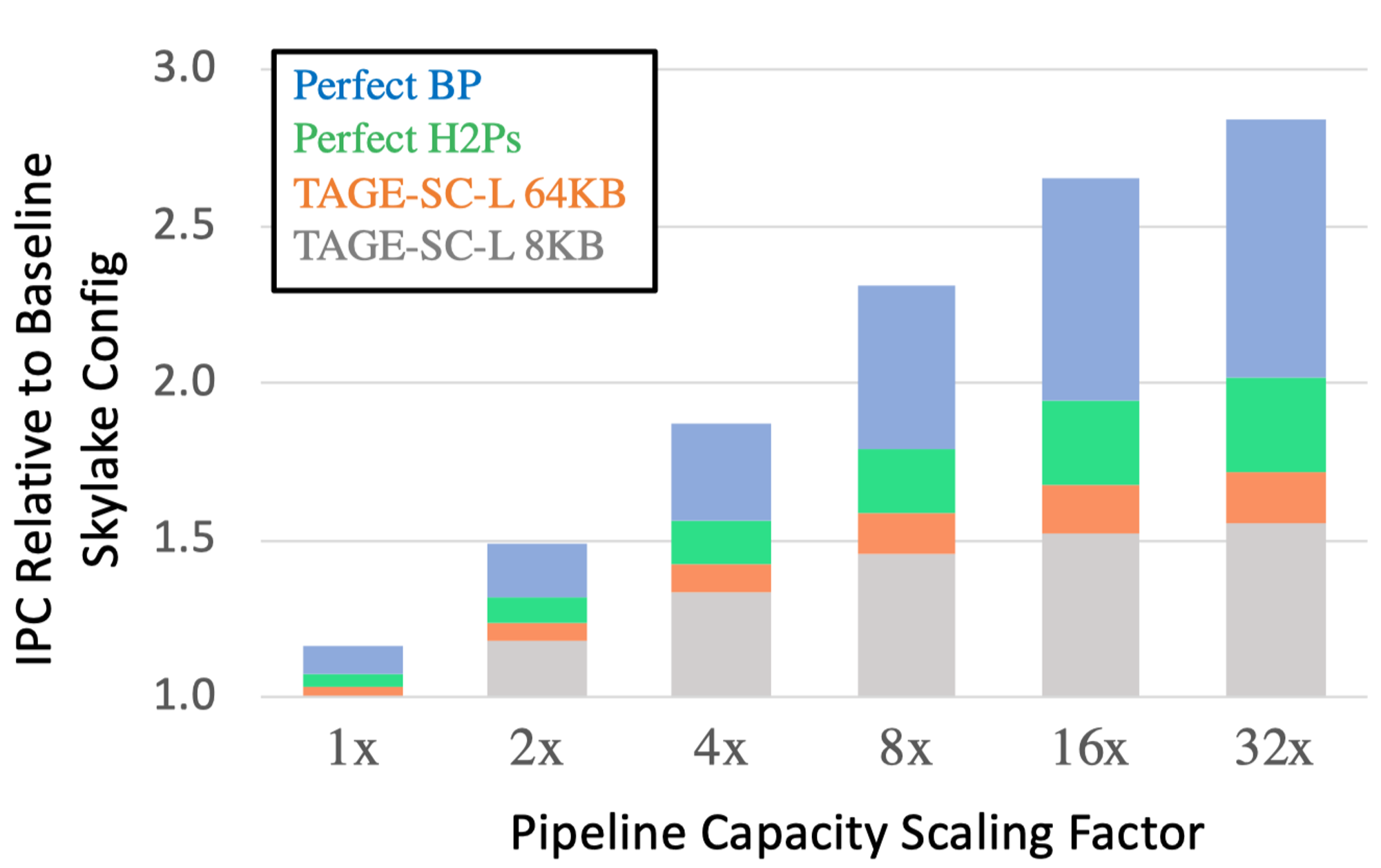
因此,虽然H2Ps在现代CPU中以SPECint 2017测试集作为基准,在提升IPC中至关重要;然而,随着扩大流水线级中的资源,执行次数很少的静态分支指令在提升性能的角色中则变得同样重要。
扩大BPU的资源并不足够
H2Ps历史信息含有大量干扰项
TAGE-SC-L 64KB配置下的分支预测器可以追踪达到3000条历史分支信息(TAGE-SC-L 8KB可以追踪1000条)。然而,更长的历史长度会带有更多的干扰信息。通过分析H2Ps当中分支之间的依赖关系(即之前已经退休的分支与H2P共享相同的操作数)来作为ground truth,对于每条H2P分支指令,定义其与某条分支指令之间具有依赖关系为:任何先前的分支指令的条件判断依赖的读操作数,该条H2P分支指令同样需要读该操作数来进行条件判断。我们发现对于一条动态执行的H2P,它对于操作数的依赖关系可以追溯到往前的5000条指令。
下表展示了SPECint 2017测试集当中H2P heavy hitter的分支指令依赖性的统计信息。
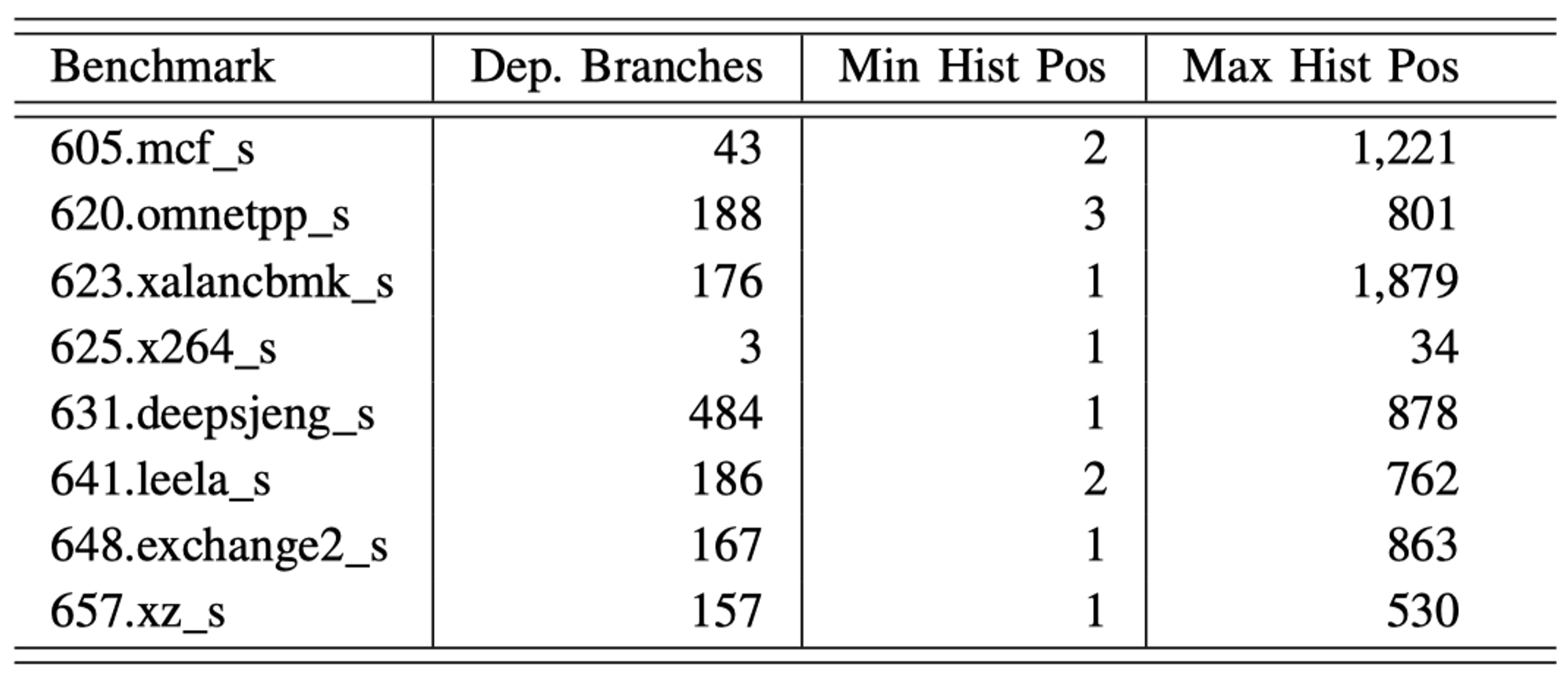
可以发现,所有的测试中即使是最长的历史长度也包含在了TAGE-SC-L 64KB配置下可以捕捉的最长分支历史长度当中。因此,TAGE-SC-L 64KB是具有有效的分支历史信息来预测这些H2P指令的,导致其较差的预测准确率是由于其他原因。
下图给出了H2P heavy hitter中具有依赖关系的分支指令在分支历史信息中的位置分布图:
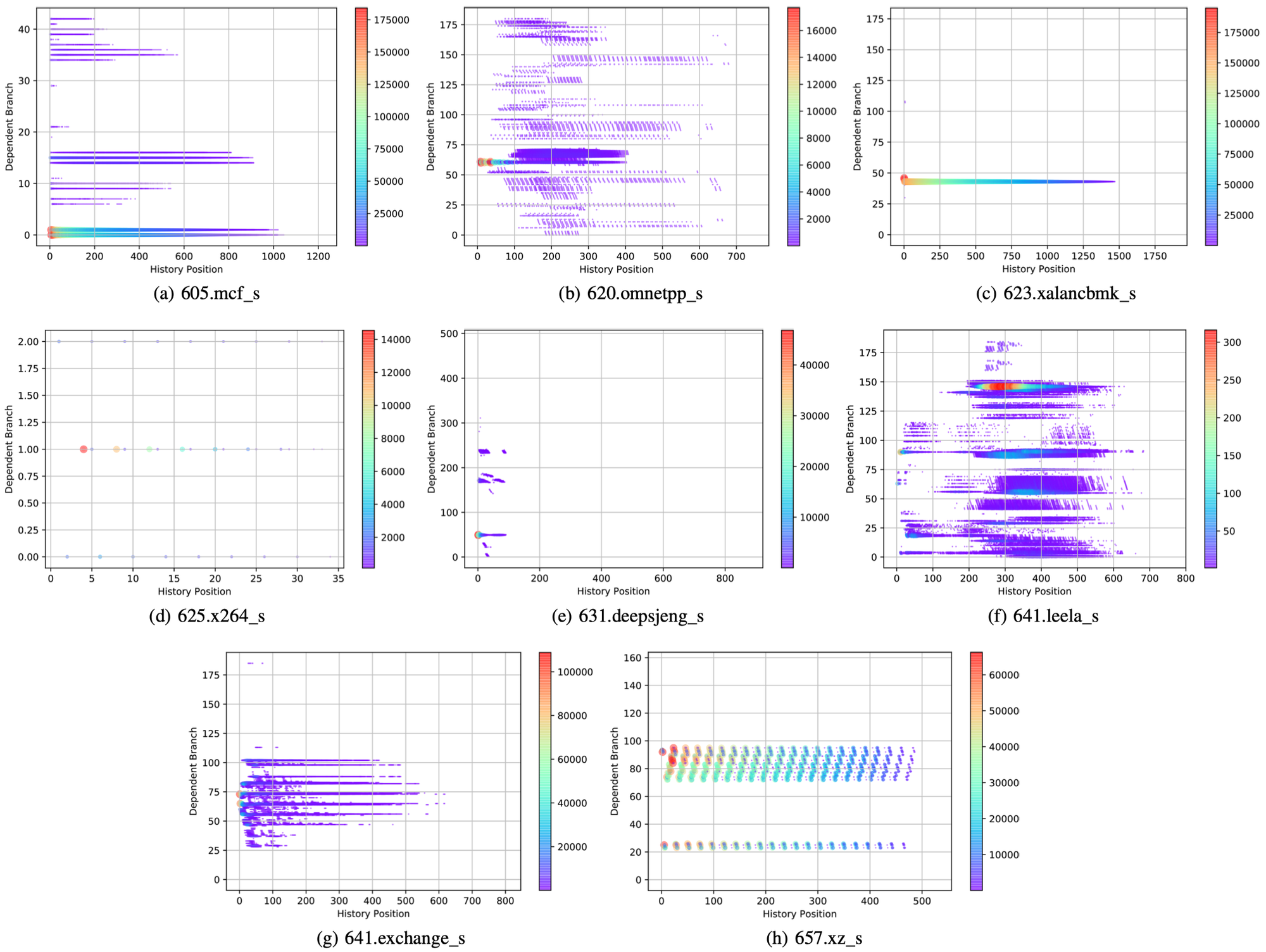
可以发现,具有依赖关系的分支指令分布非常广,并且再次出现在同一个位置上的可能性很小。因此,对于基于全局分支历史进行部分精确匹配的TAGE算法,H2Ps会带来很大的干扰项,导致其预测的准确度大大降低。
同时,还可以观察到的一个事实是,TAGE-SC-L的PPM机制对于H2P的历史信息捕捉会浪费很多存储资源,进而影响到了其他较为容易捕捉到的分支预测历史信息,并导致其需要反复进行学习,而进一步降低了整体分支预测的准确度。
较少执行分支指令缺乏可利用的分支历史信息
上文提到了,LCF应用具有大量的仅动态执行很少次的静态分支指令,TAGE-SC-L 8KB配置下的存储资源会很快被无法重用的历史信息填满。因此从理论上来说,简单的增加存储资源可以完整的学习到这些历史信息并提高IPC。
下图展示了TAGE-SC-L从8KB增大到1024KB存储资源,且等比例扩大流水线级资源下IPC的增长情况:
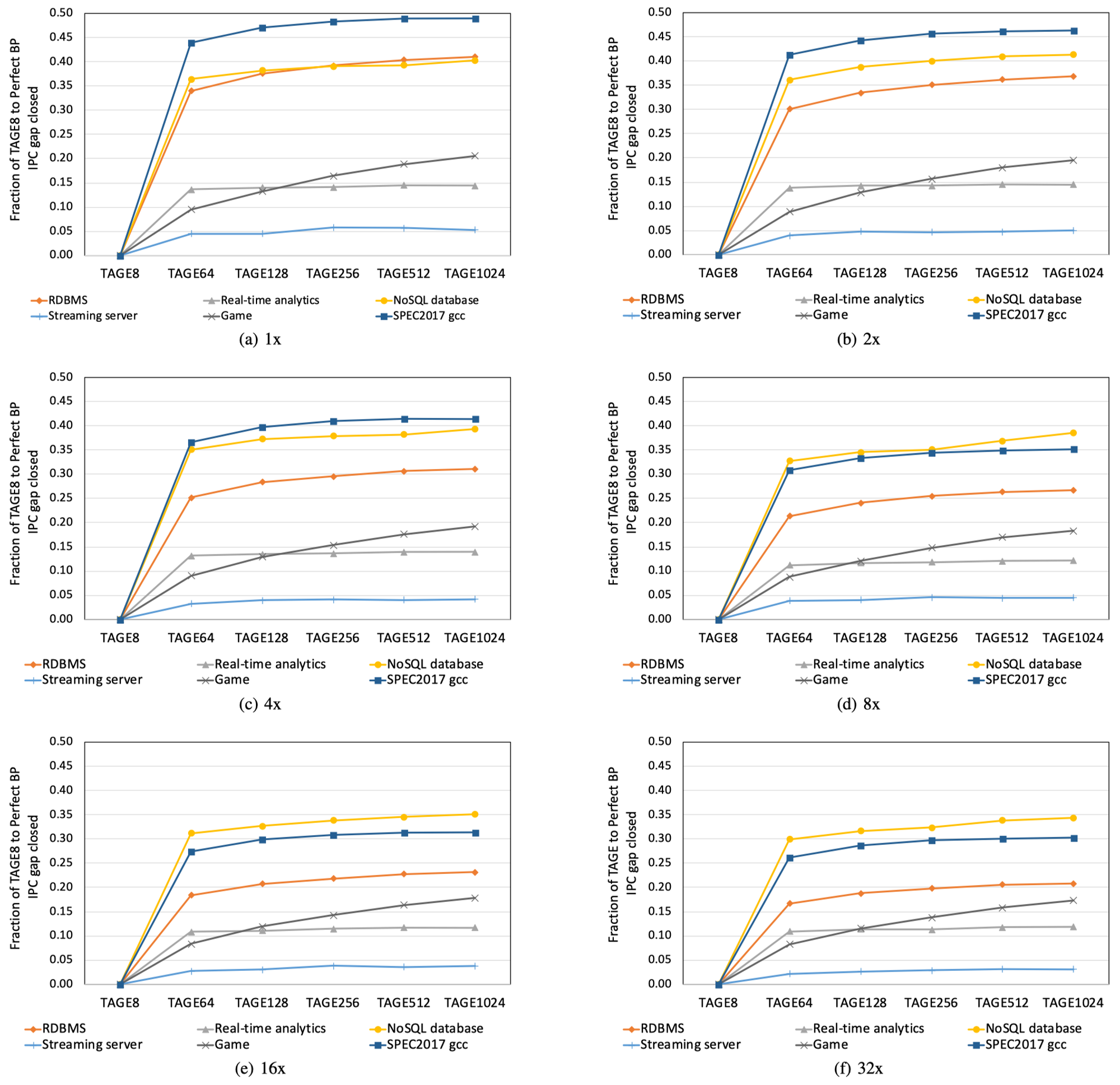
可以发现:
即使是在baseline流水线资源配置下(1x),TAGE-SC-L即使是给到1024KB的存储资源,其与完美分支预测相比能够提升的IPC数值连一半都没有(也就是说性能释放还没有预期的一半)
对于绝大多数的LCF应用来说,从8KB增大到64KB的性能回报是最大的,之后就会到达瓶颈
更糟糕的是,随着流水线资源的扩大,性能提升的回报会急剧减少。当流水线资源等比例扩大到32x时,性能释放最大只达到了期望的34%
于此同时,使用TAGE-SC-L 1024KB的配置下,在baseline流水线下对于这些较少执行的静态分支,对其先进行1000次的完美预测后,并重复进行100次完美预测,所搜集到的统计信息如图:
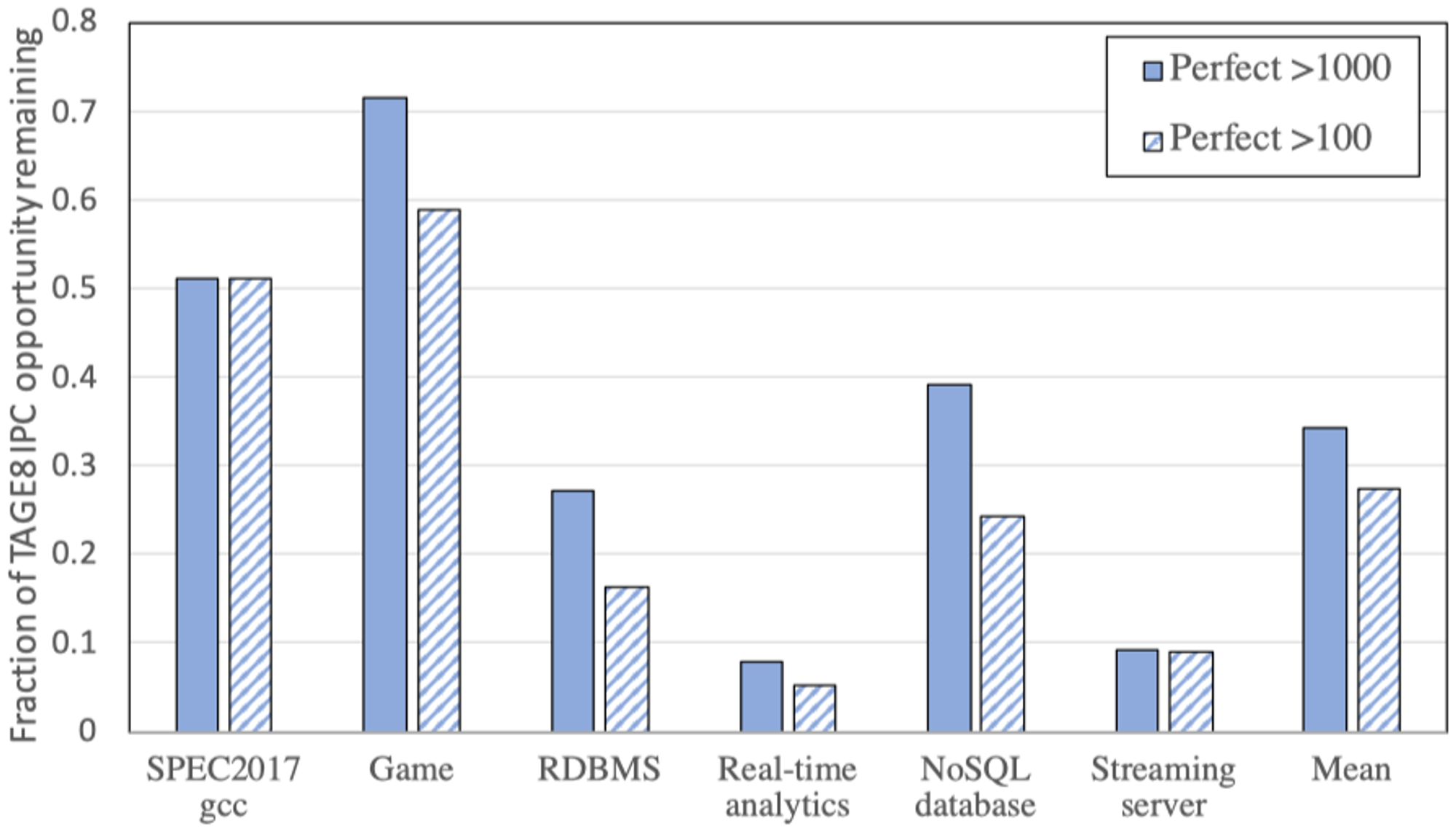
可以发现:
LCF应用中平均34.3%的性能释放来自于较少执行的静态分支指令(少于1000次)
而平均27.4%的性能释放则来自于极少执行的静态分支指令(少于100次)
综上分析,可以得出结论:对于LCF应用来说,性能释放主要来源于这些极少执行的静态分支指令,这些静态分支指令的历史信息极少,无法支持分支预测模型进行较为稳定的学习以及复用。
分支预测算法新方向
重新考虑部署分支预测算法的场景
现代所有BPU的训练以及推理都是基于在线的,也就是在处理器执行的过程中同时进行训练以及推理。然而,该方式由于资源限制,导致其所能捕捉以及学习的历史信息非常有限。如果可以允许离线进行训练,理论上可以无限制的使用各种算法/数据集来进行训练分支预测器,包括使用机器学习的算法。
使用更丰富的训练数据集
上面提到,使用离线的方式来训练BPU,则可以使用运行时间更长、更大、更多多样的输入数据集来对BPU进行训练。
对于H2P分支指令来说,离线训练可以识别出它们所依赖的分支指令作为groud truth以进行训练,此外,还可以筛选出影响历史分支信息的噪声进一步提高对H2P的预测准确度。
对于LCF应用中极少执行的静态分支指令来说,因为TAGE-SC-L的存储空间是有限的,因此它会不断重复学习→遗忘→学习这些极少执行的静态分支指令的过程。但是离线训练理论空间则是无限的,通过不断反复的执行这些极少执行的静态分支指令,以进一步稳定的学习这些分支的预测信息。
离线训练还有一个优点是,其可以学习的历史长度信息跨度非常非常长,甚至可以跨越大量的基本块以进行学习。下图展示了LCF应用中各个分支指令执行之间间隔的指令数分布:
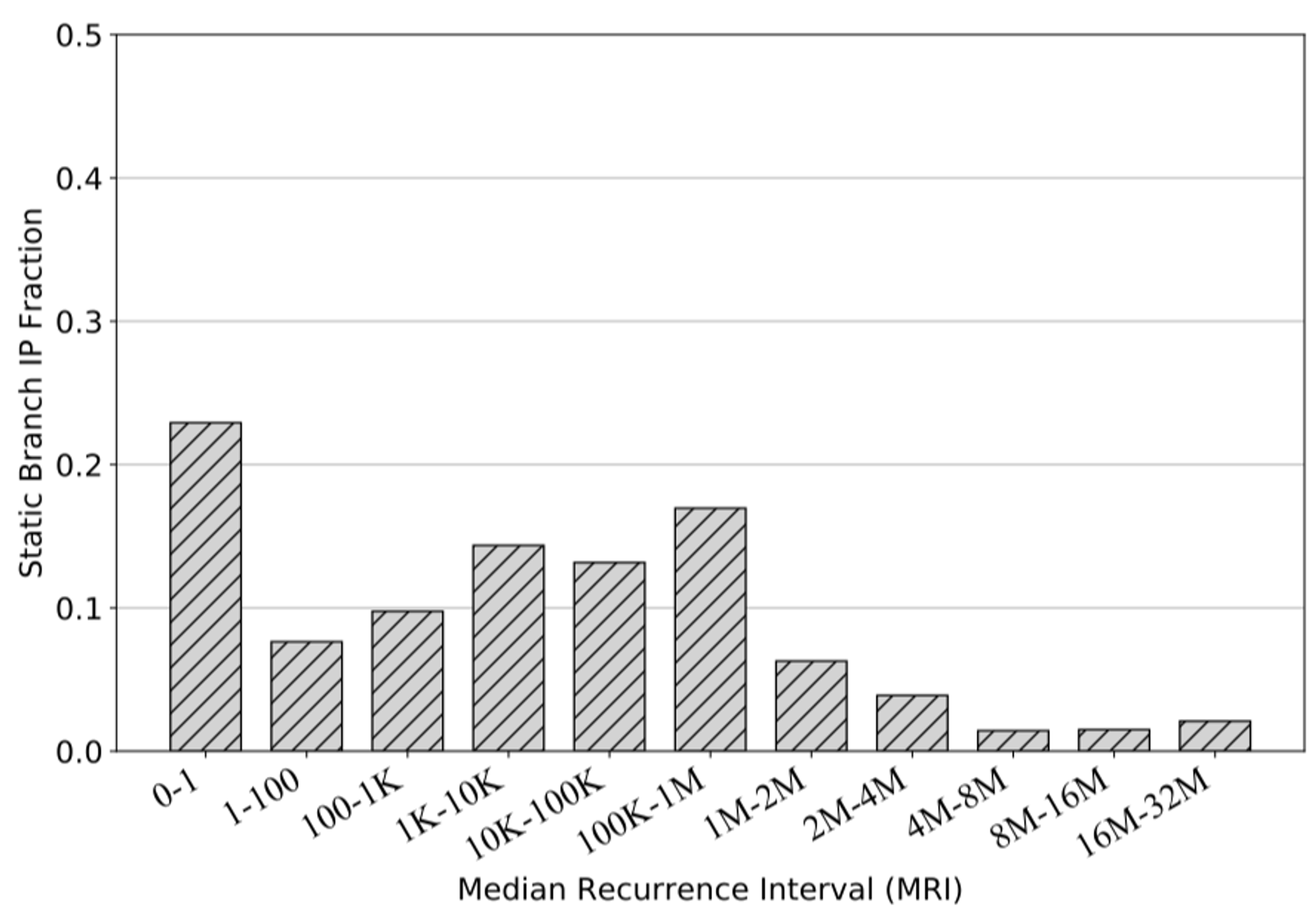
可以发现分布的中位数介于10万以及100万条指令,这对于在线训练的BPU来说是几乎不可能捕捉到的,但是对于离线训练来说则是可以实现的。
此外,离线学习还可以更为容易的学习到动态分支执行过程中的数据依赖关系。
使用机器学习模型
通过离线学习,可以去除掉训练过程中逻辑复杂度的限制,从而引入更为复杂的训练模型,如卷积神经网络(CNN),来捕捉H2P以及极少执行的静态分支指令的预测信息。在一篇使用CNN以帮助分支预测器学习的文章中,在通过多种数据集输入中训练出来的模型可以显著提高在线部署后预测器推理的准确性。
当然,使用CNN来进行推理的算法部署仍然比较复杂且昂贵,但是考虑使用低精度的二只神经网络可以在保持分支预测准确度的同时,极大的降低运算复杂度(只需要数个位操作)。
分摊离线训练开销
利用上述的离线训练/在线推理的预测器部署形式,可以允许训练的数据信息热更新到BPU当中,这对于数据中心等处理器来说非常适合。通过将已经训练好的数据放置在应用程序的metadata(如ELF中一个特殊的segment)当中,可以允许操作系统将其加载到BPU当中。这样可以不断的提高BPU的预测精确度以适应不断更新的事务应用等。