论文原文:Seznec, A., Jourdan, S., Sainrat, P., & Michaud, P. (1996). Multiple-block ahead branch predictors. ACM SIGPLAN Notices, 31(9), 116-127.
本文主要关注该思想的理论实现,文章中第5节的内容专注于如何在single I-fetch processors中实现2-ahead block branch predict的pipeline,由于文章比较久远的缘故,因此具体的pipeline实现将不会进行赘述,感兴趣的读者可以自行阅读论文原文。
Introduction
这篇文章阐述了如何实现多块先行分支预测,特别是2-ahead的BTB分支预测方法(two-block agead branch predictor),主要用于解决高性能微处理器不断发展导致的前端供指瓶颈问题。其基本的思想就是:传统的分支预测包括BTB的预测都是使用当前基本块的信息,如分支指令的地址以及分支历史等结合起来预测下一个基本块的目标地址。而2-ahead的方法则是使用当前基本块的信息来预测下下个基本块的目标地址。
当前微处理器设计有以下两种路径来旨在提高性能。
Brainiac Processors
指更激进的开发ILP(Instruction Level Parallelism)。这种微处理器会使用大量的并行执行单元来开发ILP。然而,当前(1996年)的商业微处理器的取指单元还没法完全支撑起该并发执行单元的设计。当前主流的微处理器一个时钟周期只能取一个基本块的指令,并且一般不允许跨Cache-Line取指。由于微处理器的执行速度必然不可能超越取指的速度,因此取指成为了开发ILP并行的重要瓶颈之一。
有一种解决部分该问题的方案被提出:取指的时候允许连续取多个连续的基本块(即中间没有跳转)。但为了完整的解决该问题,必须提出一种方法使得可以连续取多个非连续的基本块,为了实现该目标,微处理器前端必须具备一个周期预测多个跳转目标的能力。
此外,文章中给出了以下定义:
single I-fetch processors:一个时钟周期只能取一个基本块的微处理器;
double I-fetch processors:一个时钟周期可以取两个非连续基本块的微处理器;
multiple I-fetch processors:一个时钟周期可以取多个非连续基本块的微处理器。
Speed-demon Processors
为了达到更高的性能的目标,该类微处理器维持适中的执行单元,但是运行在很高的时钟频率上。在这类微处理器中,一个时钟周期只会dispatch一个基本块,但是分支预测单元一般会是这类微处理器的关键路径,当前的微处理器中,一般分支预测以及目标地址的生成都在同一个周期中完成,或者当发生跳转时就会插入一个空泡(DEC 21164/PentiumPro/MIPS R10000),但这样可能会降低性能。另外一个方法来解决关键路径的问题是降低预测单元的entry数量,但是这样又会降低分支预测的准确率。
本文也会给出一种方法来流水线化分支预测来解决本文提出的2-ahead BTB机制在这类微处理器中的实现,使其不会成为关键路径。
2-block Ahead Branch Predictor
在传统的分支预测机制当中,当前指令基本块的信息(如PC值)用于预测下一个基本块的PC值。本文提出一种完整的且性价比较高的2-block ahead分支预测机制。其基本思想是:使用当前基本块的信息来预测下下个基本块。该思想还可以显而易举的扩展为multi-block ahead的分支预测器,也就是用当前基本块的信息来预测更远的目标基本块。
2-block ahead分支预测包括一个2-block ahead的分支预测表(BPT)、一个2-block ahead的分支预测目标缓冲区(BTB)以及一个2-block ahead的返回栈(RAS)。大部分已经提出了的分支预测算法都可以应用到该2-block ahead的机制当中,且不会对分支预测的准确率造成显著损失,并且存放的信息也不会显著变多。
2-block ahead的分支预测器可以在double I-fetch processors中实现:两两相邻的基本块预测接下来两两相邻的目标基本块。而对于追求高频率的single I-fetch processors,则可以通过流水线化分支预测的方式来实现。
Single vs. Multiple I-fetch Processors
文章首先基于以下的体系结构建模配置来探索Single与Multiple I-fetch微处理器之间的区别:
实验结果如下:
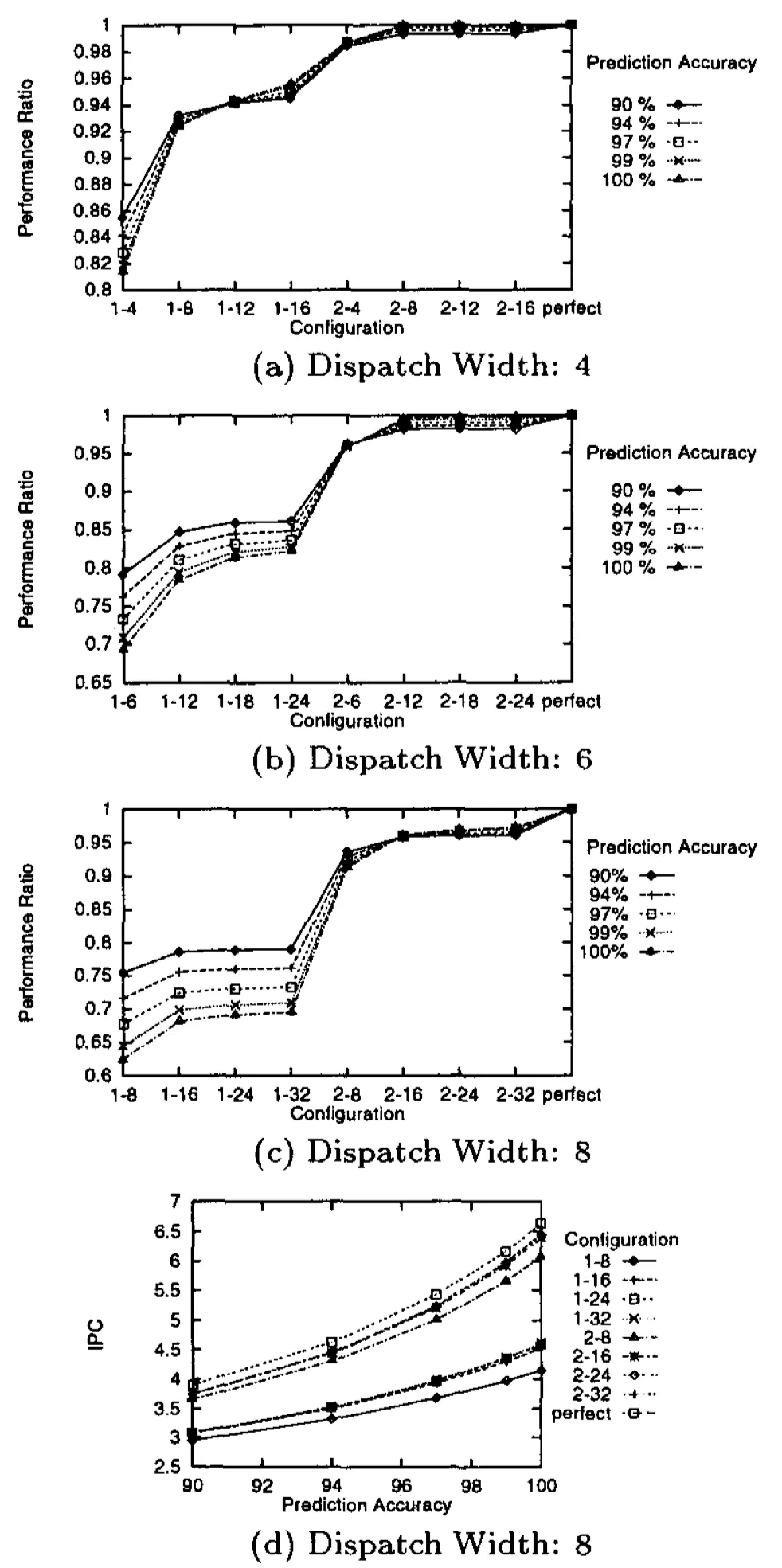
图1 Single以及Multiple I-Fetch Processors之间的性能对比
从实验结果可以得到的结论如下:
对于较长的基本块来说,Multiple I-fetch是无用的:CFP92测试集中的基本块比较长,平均每个基本块包含15条指令。对于这种浮点程序,仿真的结果表明(没有呈现在上图),一个single I-fetch的微处理器已经足够高效,无论在什么dispatch宽度或者更深的dispatch buffer下。一个8路宽的single I-fetch微处理器可以达到接近97.3%的理论最佳性能,且其预测的准确率要高于90%;
Double I-fetch对于小的基本块来说很有用:从上图可以看出来,对于4路宽的微处理器来说,使用single I-fetch策略配合至少8个entry深度的dispatch buffer来说已经足矣。然而,对于6路以及8路宽的微处理器来说,double I-fetch的策略有着巨大的提升。在8路宽的情况下,这个提升的幅度达到了20%~40%(依赖于预测的准确率,且在较深的dispatch buffer配置下)。此外,上图还可以发现,对于8路宽的微处理器来说,取大于2的multiple I-fetch策略并不有效,因为可以发现double I-fetch策略已经可以达到接近100%的理想性能了。此外,在高精度的分支预测算法支撑下,一个时钟周期取两个非连续的基本块所带来的收益提升要比只能取一个基本块要更多。最后,还可以发现双倍大小于dispatch宽度的指令缓冲区是必须的。
The 2-Block Ahead Branch Predictor

图2 2-block ahead策略下分支预测的信息依赖关系
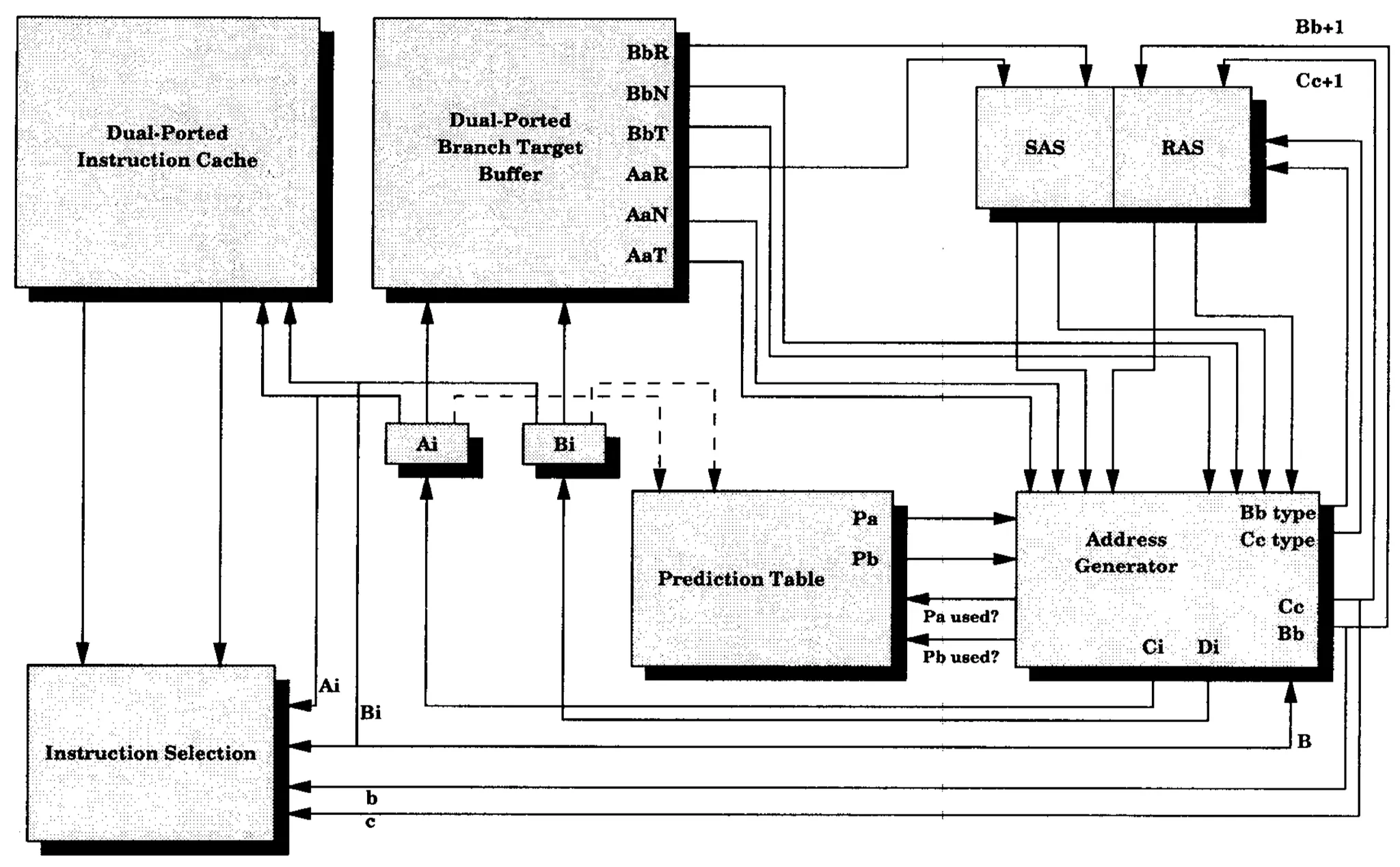
图3(a) 预测2个非连续基本块的方法
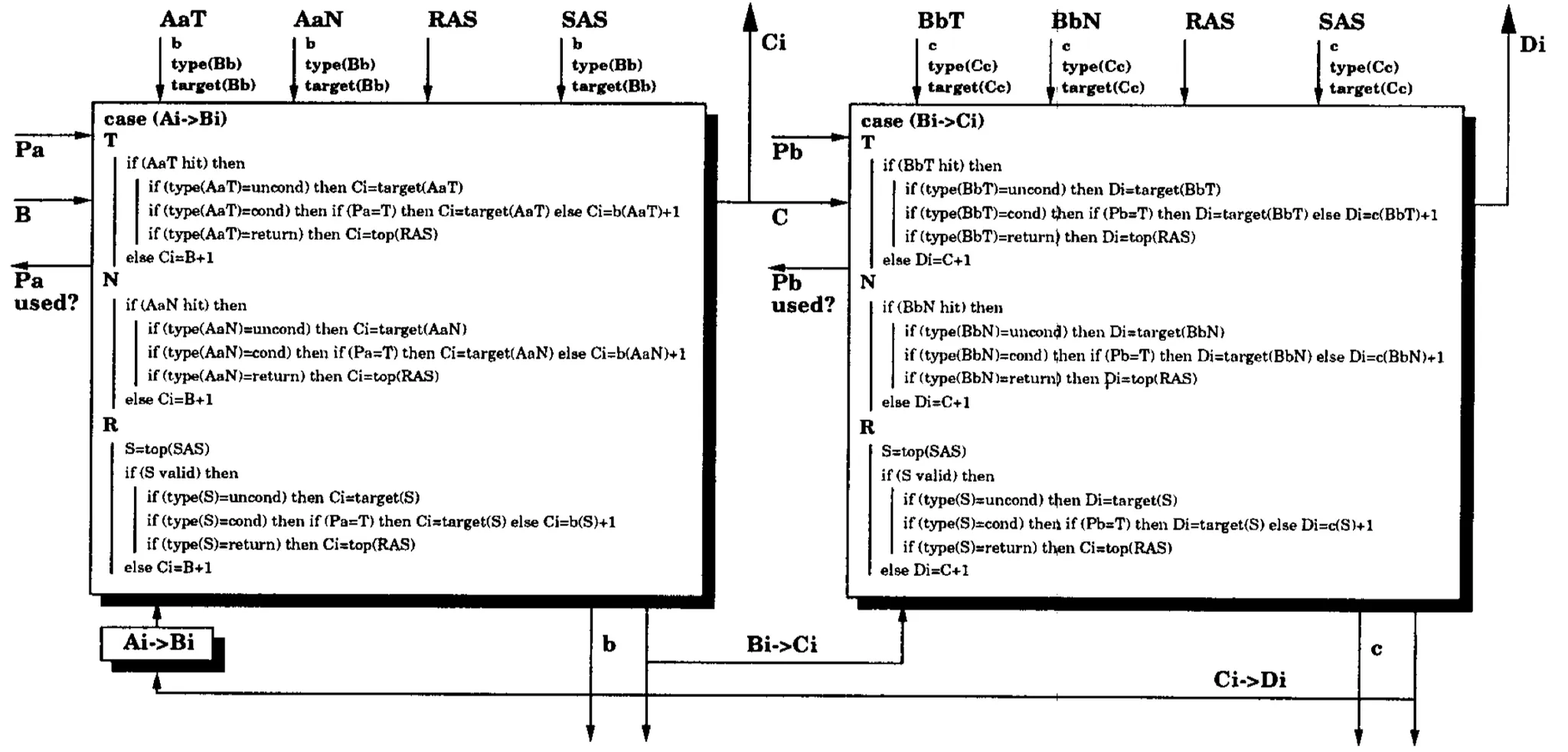
图3(b) 生成下一基本块指令地址的算法
这一章节具体阐述如何为实现double I-fetch策略的微处理器实现2-block ahead branch predictor。
在Introduction中已经提过,2-block ahead branch predictor使用当前基本块的信息来预测下下个基本块的地址。图2表示了该方法的原理,其中Ai、Bi、Ci以及Di是基本块的起始地址,Aa、Bb、Cc以及Dd是基本块中的分支指令地址。跳出这些基本块都可以是顺序执行跳出(fall-through)。当基本块A以及B被取回来时,2-block ahead branch predictor使用Aa而不是Bb来预测Ci,而Bb用于预测Di。下面分小节描述预测器中每个部分的行为。
The 2-Block Ahead Branch Prediction Table
如上文所说,在2-block ahead的策略下,对预测结果Ci进行预测的并非是(分支地址, 分支历史)为(Bb, Hb)的信息,而是(Aa, Ha)。当然,这种策略下并不限制预测的算法。在图3中,Pa以及Pb表示使用(Aa, Ha)以及(Bb, Hb)索引BPT分别得到的预测结果。
The 2-Block Ahead Branch Target Buffer
BTB entry description
2-block ahead BTB记录着给定分支的类型以及与它上上个基本块地址关联的信息。
当一个taken branch Bb预测错误或者被错误的取指时,一个BTB的entry会被分配来记录:
其目标地址(Ci);
类型(有条件分支、无条件分支、间接跳转或者返回指令,可以是2-bit);
基本块(B)中的分支地址(b)。
与传统的设计不同,该新分配的BTB entry不会打上Bb地址的标签,或者包含该基本块B的cache-line,而是关联上Aa的地址,也就是上上个基本块的最后一个指令的地址。索引BTB使用的是:
地址Aa;
Aa→Bi之间转移的类型:T(Aa是非return类型的跳转分支指令)、N(Aa是非跳转的条件分支指令或者一条非分支指令)以及R(Aa是一条Call,一般是间接跳转指令)。
如果基本块A中没有分支指令,则Aa为基本块最后一条指令的地址。
BTB read
本节阐述在double I-fetch的微处理器中,如何读取2-block ahead的BTB。首先明确每个时钟周期一开始就可用的信息:
地址Ai以及Bi是可用的;基本块A以及B的地址用于访问BTB以及ICache;
基本块A中的分支地址a以及Aa→Bi之间的转移类型X在上一个周期就可以得到。
因此,所有用于计算目标地址Ci的信息都已知,现在我们可以检查BTB entry AaX来计算Ci,该entry记录着分支Bi的目标地址Ci以及其转移的类型。整个流程可以参照图3。
需要注意的是,计算目标Di得某些信息在每个时钟周期的一开始并不可用:基本块B的分支指令地址b以及Bb→Ci的转移类型Y,这些信息可以在计算Ci的过程中获得:
若AaX命中某个BTB的entry,则信息来源于该BTB entry;
若AaX没有命中BTB,则假设基本块B中没有分支指令,b是该基本块中最后一条指令,即Y为fall-through。
当得到上述的结果时,BbY entry的tag比对就会开始,而目标地址Di的生成逻辑与Ci相似。
Storage cost
单个地址Aa可能会关联到两个不同的entry:AaT记录着当分支a为taken的时候跳转目标基本块的下一个基本块的地址,AaN记录着当分支a为fall-through的时候下一个基本块再下一个基本块的地址。
同时,如果Bb具有多个前导基本块,那么可能还会有多个冗余的BTB entry被分配,但是根据文章中的仿真表明,这种场景很少,与普遍的BTB相比区别很小。
Associativity
同样,由于绝大部分的条件分支在大部分情况下都是taken或者fall-through,因此大部分的BTB entry都只会记录AaT或者AaN,所以在该策略下BTB的关联性与普遍的BTB没有太大区别。
Coping with Procedure Returns
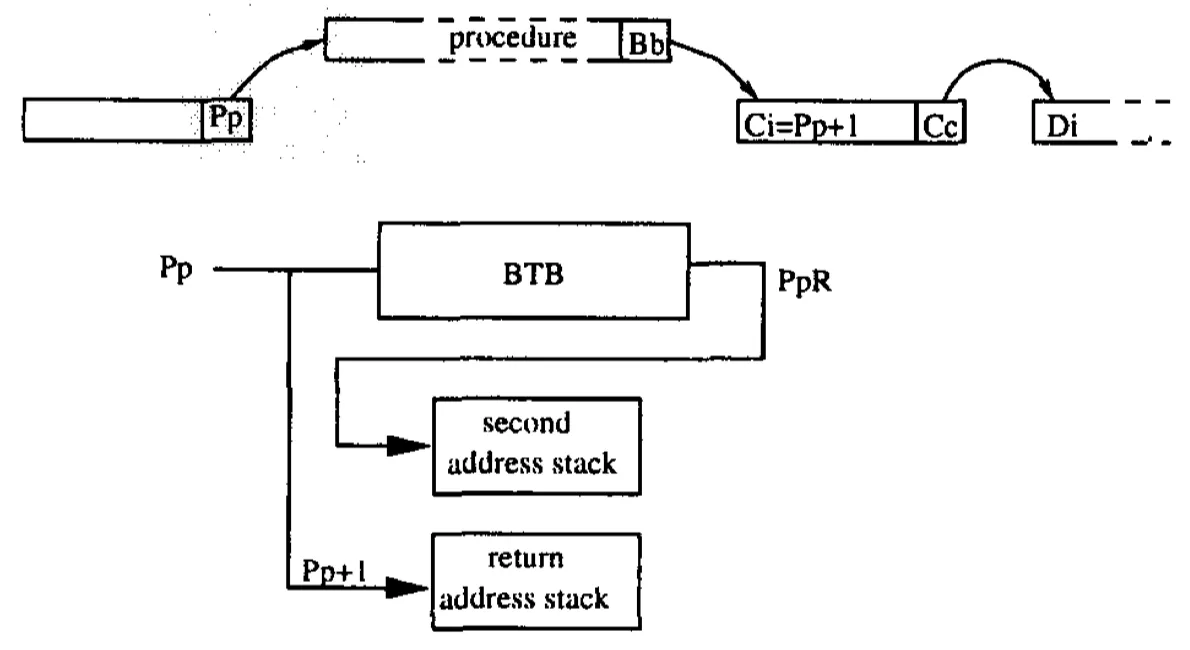
图4(a) Call指令Pp在取指时检测到,两个RAS被写入
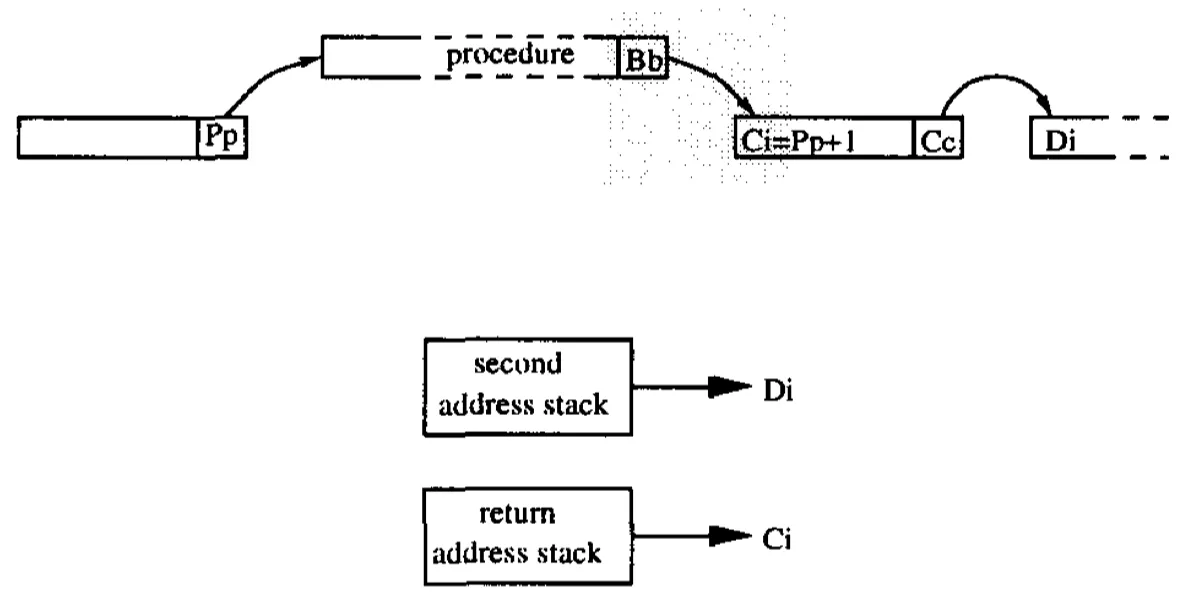
图4(b) Return指令Bb在取指时被检测到,则两个RAS被同时读取
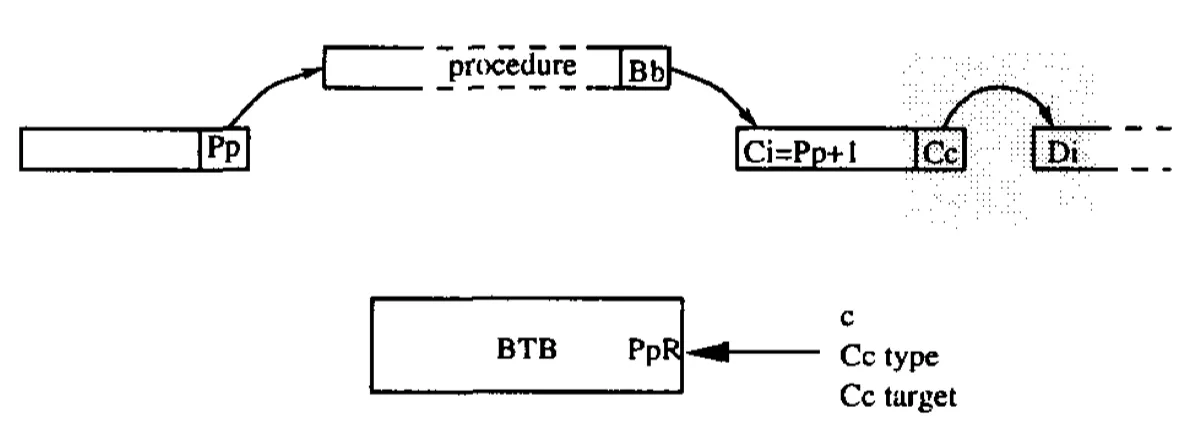
图4(c) 分支Cc预测错误,BTB被更新
在2-block ahead的分支预测策略当中,若基本块B的分支b是一条return,那么Bb也应该要预测得到地址Di。但是显然,Di应该更依赖于Bb的返回目标Ci,然而虽然是同一条Bb指令,但调用该过程块的调用点可能会非常多,换言之,Ci是有很多种可能性的。因此,这里最恰当的解决办法应该是要看是谁调用了过程块B(或者说应该跳回到哪个Ci),而不是仅看Bb。
Second Address Stack
正如上面提到的,地址Di显然更依赖于Bb的返回目标Ci。可以确定的一点是,调用基本块B的call指令Pp=Ci-1已经进入指令流当中了,因此,实际上我们可以将Di的信息关联到过程调用Pp当中。为了实现这种策略,一个特殊的entry类型R引入到BTB当中,如图4所示。
当基本块C预测错误时,一个PpR的BTB entry被分配来记录Cc的branch信息,而不是BbT的entry。
当Pp被取指时,BTB会查找该PpR的entry,该entry的信息必须要保留到当return指令Bb被取指时。为了达到这种目的,会使用第二个RAS,也就是SAS。若PpR命中,一份PpR的拷贝会被push进去SAS中,否则,一个无效的entry会被push进去。
当目标地址Ci从RAS中弹出的时候,SAS中同样会弹出目标地址Di,来达到2-ahead block predict的效果。
A further optimization
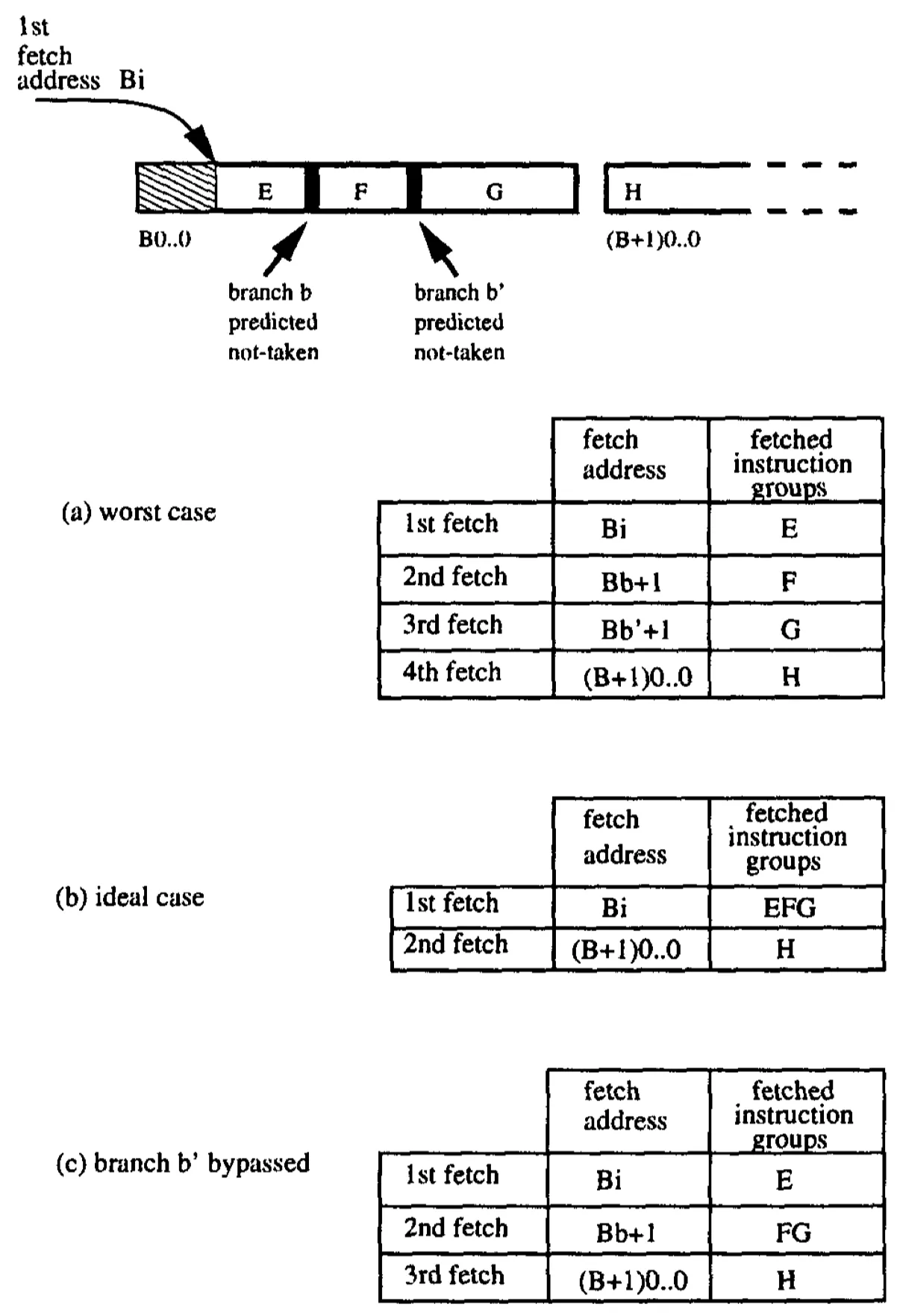
图5 旁路not-taken的分支
在使用2-block ahead branch predictor的时候,如果分支指令Bb预测为not taken,那么接下来预测的程序块将从Bb+1开始。然而,Bb可能并非是该基本块的最后一个指令,当指令cache-line从ICache中取出来的时候,很有可能Bb后续的很多指令也会被一并取出来。如图5所示,如果不做特殊的优化处理,程序块E、F以及G都会并行的在同一个时钟周期中被fetch出来,但是无论b预测的结果是什么,块F以及G都会被丢弃掉,然而若b预测为not taken,那么实际上F以及G都是有用的,这种做法浪费了ICache的带宽。
图5a展示了最糟糕的场景,即使b、b‘都预测为not taken,第1次的fetch实际上就已经把块E、F、G都拿出来了,但是由于分支预测的存在,最后一共进行了对同一个cache-line的3次fetch。图5b是最理想的场景,在一次fetch中就把EFG都送出去。但是,这种情形基本上很难实现。
这里提出一种较为折中的解决方案:当识别到当前预测的分支指令是这个cache-line最后的一个分支指令且预测为not taken时,则将整个cache-line在当前周期都bypass出去,如图5c所示。这里使用了一个L信息来记录:当前的分支指令时当前cache-line的最后一条指令信息。如果当前预测的分支指令为not taken且拉高了L标识,则余下的整个cache-line都将会发送给后续的pipe。
2-Block Ahead Branch Predictor in a double I-fetch processor
当微处理器前端实现一个double I-fetch的取指策略时,ICache必须实现为双端口,或者至少是interleaved的。同样,BPT以及BTB都必须实现为双端口或者interleaved的。
此外,RAS以及SAS都必须能够在每个时钟周期一起提供2条目标地址:
当Bb→Ci是一条return时,RAS负责给出目标地址Ci以及Cc→Di的转移类型,SAS负责给出目标地址Di;如果Cc→Di也是一条return,那么还需要第二次读RAS;
当Aa→Bi时一条return时,SAS负责给出目标地址Ci,如果Bb→Ci也是一条return,那么还需要第二次读SAS来给出Di。
同时,如果Bb→Ci以及Cc→Di都是call,那么这两个栈也需要能够在每个时钟周期接收两次push更新。
Experimental Results
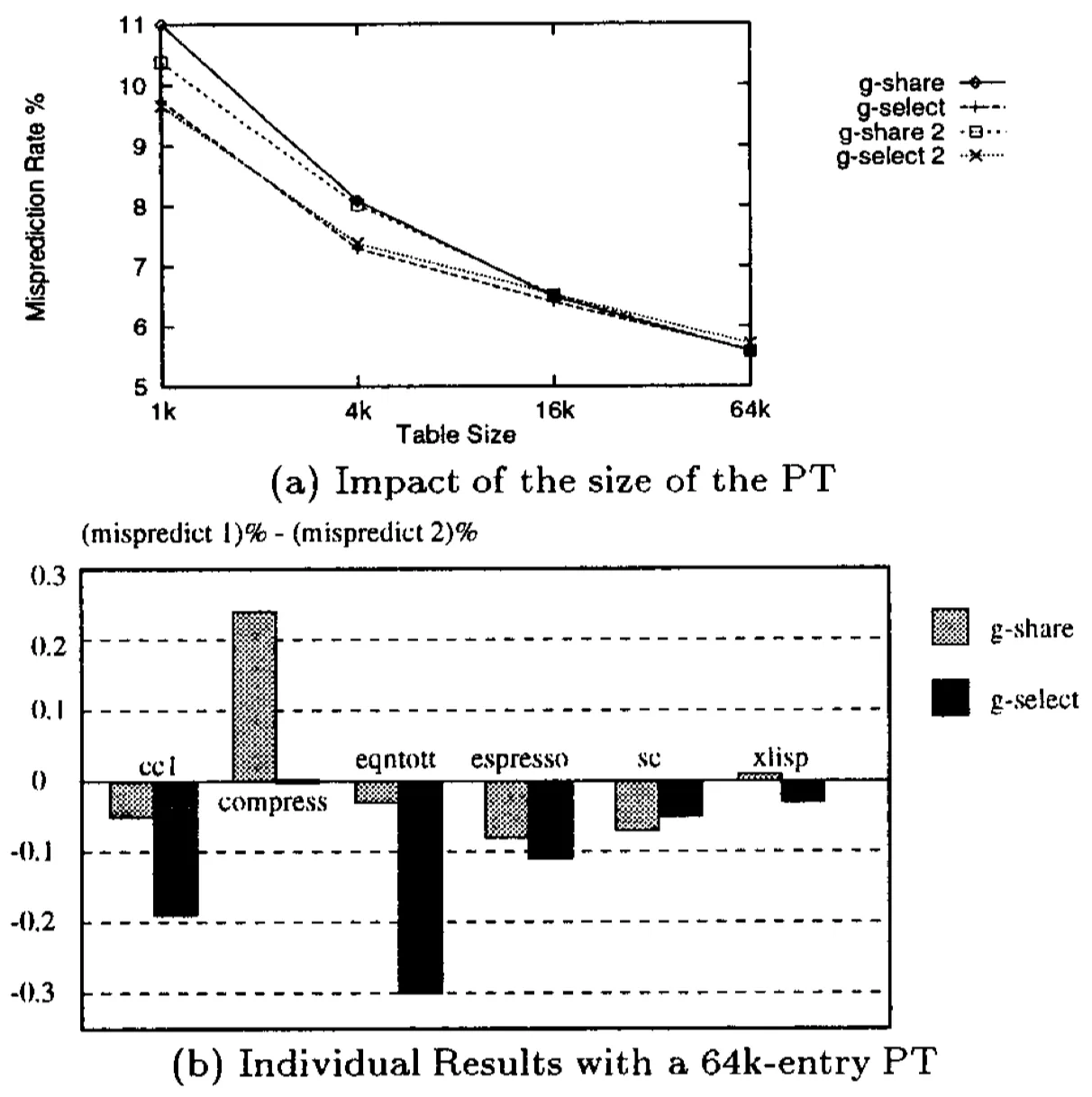
图6 分支预测错误率
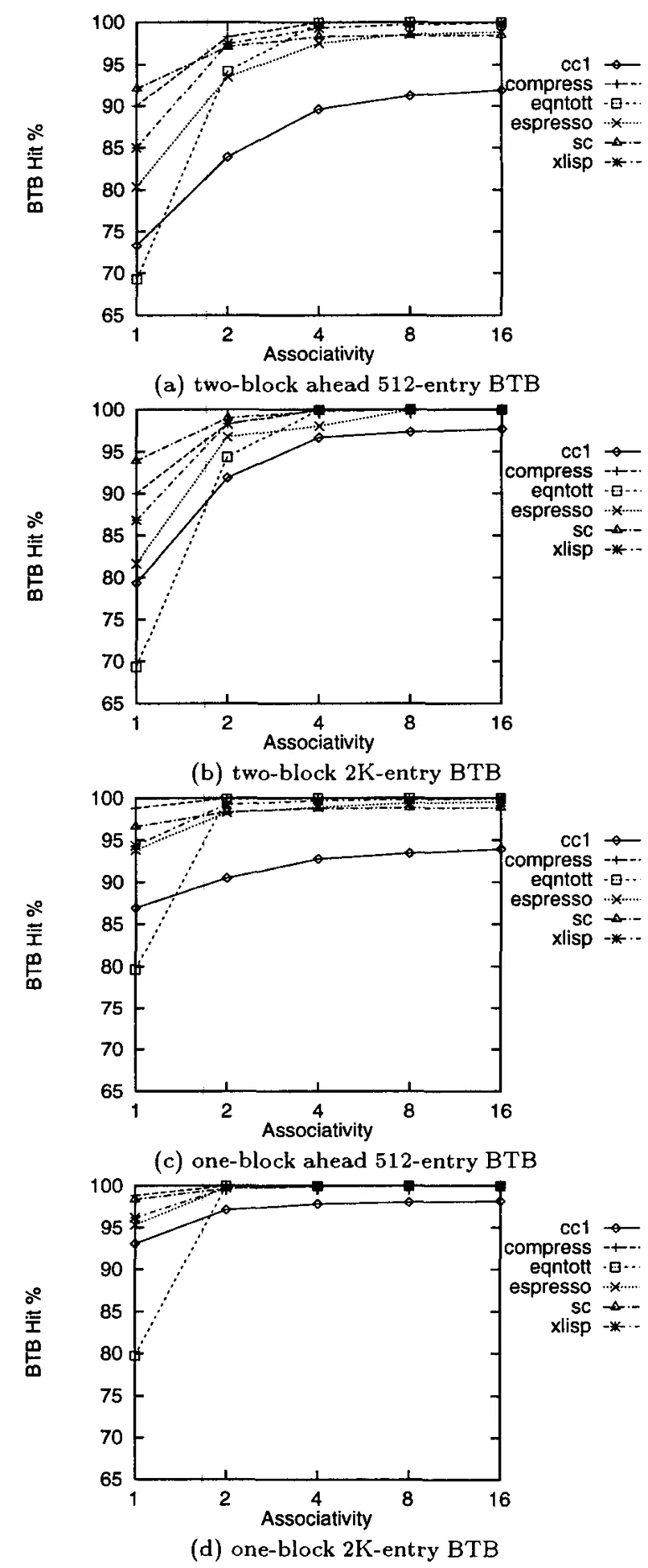
图7 BTB命中率与相联度以及深度的实验结果
从上述的实验结果可以看出:
2-block ahead branch predictor的预测准确率性能与传统的1-block ahead branchpredictor类似,两者之差不超过0.3%;
从图7a以及7b可以看出,对于2-ahead branch predictor的BTB,当BTB的相联度为4时,基本可以达到近乎100%的BTB命中率,相比1-ahead branch predictor的BTB,其相联度为2时就基本可以达到近乎100%的BTB命中率。同时,可以发现无论是2-ahead还是1-ahead的branch predictor,其命中率的区别也无几。