XiangShan是中科院计算所的高性能RISC-V微处理器项目,基于其开源的特性,可以从中一窥高性能微处理器的一些设计理念以及思路等。本系列的文章将从XiangShan开源的微处理器核的前端(除译码器外)代码出发,尝试浅析其分支预测、取指以及指令缓存的微架构设计等。更多关于XiangShan的信息可以参考其官方文档。
系列文章导航:
文档
在剖析源码前,不妨先过一下官方文档对整体前端以及BPU、uBTB的描述。
总体架构
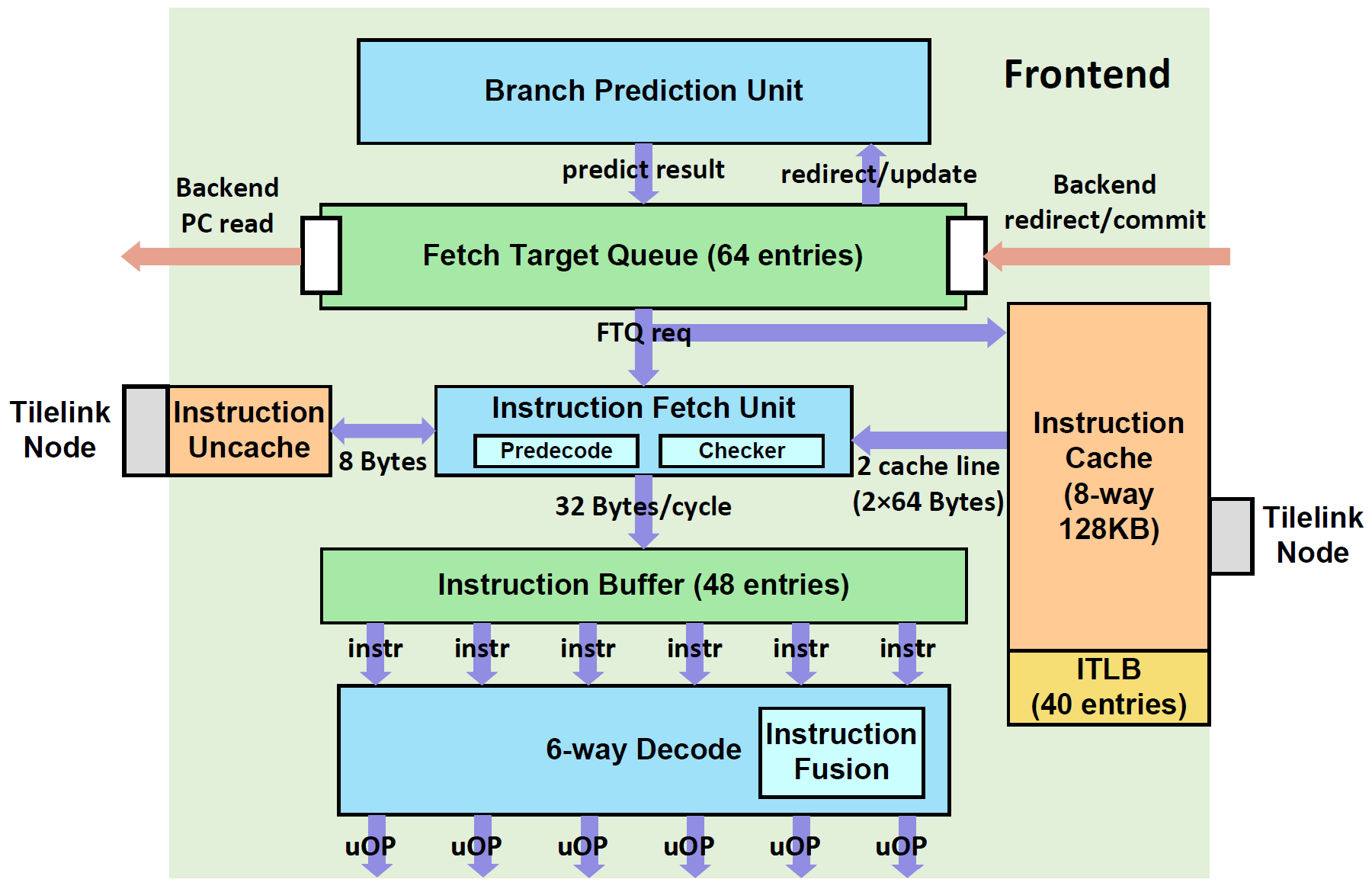
采取了一种分支预测和指令缓存解耦的取指架构,分支预测单元提供取指请求,写入一个队列,该队列将其发往取指单元,送入指令缓存。 取出的指令码通过预译码初步检查分支预测的错误并及时冲刷预测流水线,检查后的指令送入指令缓冲并传给译码模块,最终形成后端的指令供给。
BPU整体架构
BPU的流水线如下所示:
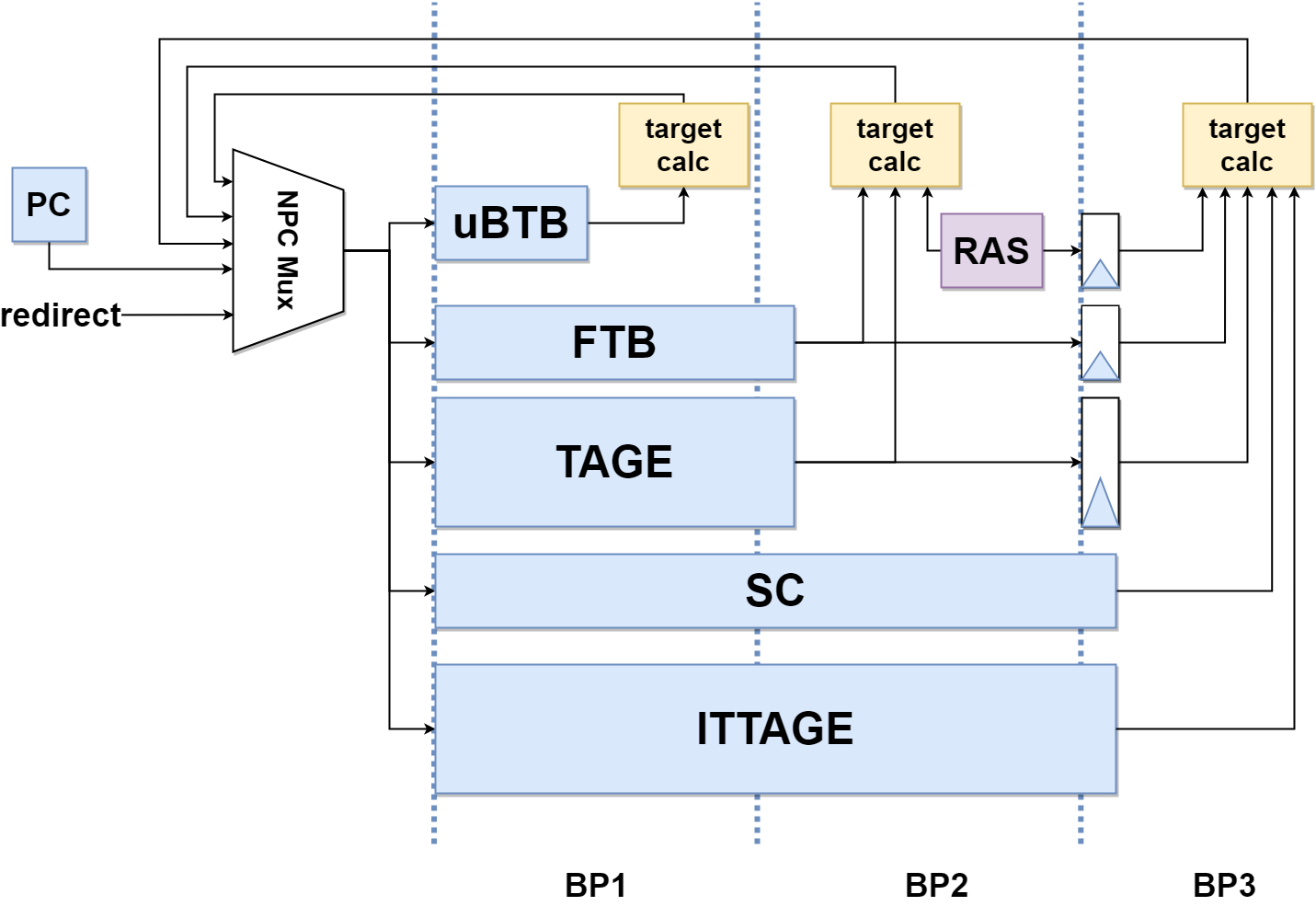
由两部分组成:
- 下一行预测器(NLP):uBTB,提供无空泡的预测
- 精确预测器(APD):FTB+TAGE+SC+ITTAGE+RAS
每一个流水级都会产生新的预测内容,分布于不同流水级的预测器组成了一个覆盖预测器。
下一行预测器:uBTB
使用PC的低位以及分支历史异或索引存储,表中内容提供了最精简的预测,包括:
- 下一个预测块的起始地址
nextAddr - 这个预测块是否发生分支跳转
taken - (若跳转)跳转指令相对起始地址的偏移
cfiOffset - 提供分支指令相关信息以更新分支历史:是否在条件分支跳转
takenOnBr、块内包含分支指令的数目brNumOH。
摒弃使用tag匹配的方法,在这种情况下,处理错误hit的场景(把没有分支指令的预测块预测为另一个跳转的块)通过一个存储结构,通过PC直接索引,其中存储当前PC是否可能存在有效的分支指令进行预测。它的查询结果为当前取指的PC是否有被写入过,如果未被写入则下一个PC预测为当前PC加预测块宽度。
下面就开始进入实际RTL代码的浅析环节。
概述
源代码:/xiangshan/frontend/uBTB.scala
Xiangshan的uBTB采用的是单一一级的BTB结构,且辅以一个FallThruPred的表来记录当前PC的预测块中是否存在branch。uBTB以及FallThruPred都使用SRAM来作为存储单元。
参数
trait MicroBTBParams extends HasXSParameter with HasBPUParameter {
val numEntries = UbtbSize // 256
val ftPredBits = 1
val ftPredSize = FtbSize // 2048
val ftPredFoldWidth = 8
val ftPredDecayPeriod = 2048 // each time decay an entire row
def ubtbAddr = new TableAddr(log2Up(numEntries), 1)
}
numEntries: uBTB的大小,为256个entryftPredBits: FallThruPred表中预测信息的宽度,为1 bit,指示当前PC的预测块是否存在branchftPredSize: FallThruPred表的大小,为2048项ftPredFoldWidh: FallThruPred表的way数,也就是SRAM中每个set包含的项数ftPredDecayPeriod: 周期性reset FallThruPred表中一个set的机制,每2K个cycle进行一次reset
存储结构
FallThruPred
val nRows = ftPredSize / ftPredFoldWidth // 2048 / 8 = 256
val ram = Module(new SRAMTemplate(UInt(ftPredBits.W), set=nRows, way=ftPredFoldWidth,
shouldReset=false, holdRead=true, singlePort=true))
// SyncReadMem used in SRAMTemplate:
// val array = SyncReadMem(set, Vec(way, wordType))
256个set,每个set为8路,每一路都只有一个bit,更直观来说的结构就是SRAM有256行,每行为8-bits。
uBTB
val dataMem = Module(new SRAMTemplate(new NewMicroBTBEntry, set=numEntries, way=1,
shouldReset=false, holdRead=true, singlePort=true))
直接映射的SRAM,大小为256个entry,每个entry为NewMicroBTBEntry类中定义,各字段如下所示:
// FetchWidth = 8
val PredictWidth = FetchWidth * (if (HasCExtension) 2 else 1)
// Enable C Extension: PredictWidth = 16
// XiangShan predict block size = 32B, maximum instr is 16
class NewMicroBTBEntry(implicit p: Parameters) extends XSBundle with MicroBTBParams {
// val valid = Bool()
val nextAddr = UInt(VAddrBits.W) // 39-bit, could be target or fallThrough
val cfiOffset = UInt(log2Ceil(PredictWidth).W)
val taken = Bool()
val takenOnBr = Bool()
// numBr = 2, maximum br predict in one cycle
val brNumOH = UInt((numBr+1).W) // used to speculative update histPtr
// ...
}
nextAddr: 下一个预测块的起始地址cfiOffset: 跳转指令相对起始地址的偏移taken: 这个预测块是否发生分支指令跳转takenOnBr: 是否在条件分支跳转brNumOH: 块内包含的分支指令数目(独热编码表示的0-2)
FallThruPred
FallThruPred是一个用于存储当前PC对应的预测块中是否存在branch的表,表的大小为2048,使用当前PC哈希后进行索引:
val instBytes = if (HasCExtension) 2 else 4
val instOffsetBits = log2Ceil(instBytes)
def getFtPredIdx(pc: UInt) = {
// require(pc.getWidth >= instOffsetBits + 2 * log2Ceil(ftPredSize))
// hash twice as more bits into idx
(0 until 2).map {i =>
(pc >> (instOffsetBits + i * log2Ceil(ftPredSize)))(log2Ceil(ftPredSize)-1,0)
}.reduce(_^_)
}
// Pass to FallThruPred
fallThruPredRAM.io.ridx := getFtPredIdx(s0_pc)
// Pass to SRAM, select row
ram.io.r.req.bits.setIdx := io.ridx >> log2Ceil(ftPredFoldWidth)
折叠的方式为:
从FallThruPred中读取的信息将会影响BTB是否输出从uBTB SRAM中读取的预测信息。
FallThruPred的更新也很直白,只要对比从FTQ返回的update信息是否有效且返回的update信息中当时所做的ftPred信息是否与update信息中准确的预测信息pred_hit相同即可,如果不同就进行更新:
val u_ftPred = u_meta.ftPred.andR
val u_ftMisPred = u_ftPred ^ update.pred_hit
fallThruPredRAM.io.wen := u_ftMisPred && RegNext(io.update.valid)
fallThruPredRAM.io.widx := getFtPredIdx(u_pc)
fallThruPredRAM.io.wdata := satUpdate(u_meta.ftPred, ftPredBits, true.B)
这里需要注意的是,由于只有当该预测块中存在branch才会更新,因此更新总是倾向于taken的,如果本来就没有branch,那就没有必要更新。
周期性重置
FallThruPred表实现了一个定期重置一行row的机制:
val reset_wdata = WireInit(0.U.asTypeOf(Vec(ftPredFoldWidth, UInt(ftPredBits.W))))
val decay_timer = RegInit(0.U(log2Ceil(ftPredDecayPeriod).W))
decay_timer := decay_timer + 1.U
val doing_decay = RegNext(decay_timer.andR())
val decay_wdata = reset_wdata
val decay_idx = RegInit(0.U(log2Ceil(nRows).W))
decay_idx := decay_idx + doing_decay
每2k个周期重置SRAM中的一行,重置的idx每次递增1,也就是说,每2k个周期重置row 0, 1, 2, …。
uBTB
uBTB是NLP的主预测单元,使用一个256-entry的SRAM存储相关的预测信息。
索引该SRAM的index使用PC与折叠后的全局分支历史哈希得到:
// pc[8:1]
def getIdx(pc: UInt) = pc(log2Ceil(numEntries)+instOffsetBits-1, instOffsetBits)
// pc[8:1] ^ folded_hist[7:0]
def get_ghist_from_fh(afh: AllFoldedHistories) = afh.getHistWithInfo(fh_info)
val s0_data_ridx = getIdx(s0_pc) ^ get_ghist_from_fh(io.in.bits.folded_hist).folded_hist
s0_pc的生成逻辑
根据源码的理解得到的生成逻辑如下所示:
s0_pc := PriorityMux(Seq(
s2_redirect && !s3_redirect && !do_redirect.valid -> resp.s2.getTarget,
s1_valid && !s2_redirect && !s3_redirect && !do_redirect.valid -> resp.s1.getTarget,
s3_redirect && !do_redirect.valid -> resp.s3.getTarget,
do_redirect.valid -> do_redirect.bits.cfiUpdate.target,
!s1_valid && !s2_redirect && !s3_redirect && !do_redirect.valid -> s0_pc_reg
))
其中优先级自上而下递减。
获取uBTB预测信息
def fromMicroBTBEntry(valid: Bool, entry: NewMicroBTBEntry, pc: UInt) = {
this.valid := valid
this.nextAddr := Mux(valid, entry.nextAddr, pc + (FetchWidth*4).U)
this.cfiOffset := entry.cfiOffset | Fill(cfiOffset.getWidth, !valid)
this.taken := entry.taken && valid
this.takenOnBr := entry.takenOnBr && valid
this.brNumOH := Mux(valid, entry.brNumOH, 1.U(3.W))
}
val shouldNotFallThru = fallThruPredRAM.io.rdata.andR()
val resp_valid = RegEnable(validArray(s0_data_ridx), io.s0_fire && !update_valid)
io.out.resp.s1.minimal_pred.fromMicroBTBEntry(
resp_valid && shouldNotFallThru && !lastCycleHasUpdate && io.ctrl.ubtb_enable,
dataMem.io.r.resp.data(0), s1_pc
)
从uBTB SRAM中读取出来的信息有效的条件为:
- 使用当前idx从SRAM中读取的entry是有效的
- s0阶段使能
- 当前uBTB不需要进行更新
- 当前
s0_pc对应的预测块预测存在branch - 外部控制信号使能ubtb
对应uBTB表项对s1的resp处理为:
nextAddr: 若valid有效,则将entry中的nextAddr给到s1,否则给出顺序的地址brNumOH: 若valid有效,则将entry中的brNumOH给到s1,否则给3’b001(没有br)
更新uBTB
// Update logic
val update_mispred = io.update.bits.mispred_mask.reduce(_||_)
val update_redirected = io.update.bits.from_stage === BP_S2
val update = RegNext(io.update.bits)
val u_valid = RegNext(io.update.valid && (update_mispred || update_redirected))
update_valid := u_valid
val u_pc = update.pc
val u_br_taken_mask = update.full_pred.br_taken_mask
val u_meta = update.meta.asTypeOf(new MicroBTBOutMeta)
val u_data = Wire(new NewMicroBTBEntry)
u_data.fromBpuUpdateBundle(update)
val u_idx = getIdx(update.pc) ^ get_ghist_from_fh(update.folded_hist).folded_hist
dataMem.io.w.apply(u_valid, u_data, u_idx, 1.U(1.W))
when (u_valid) {
validArray(u_idx) := true.B
}
更新的信息都将打一拍,更新信息有效的条件为:update.valid有效且uBTB预测存在错误或者需要redirect。