本文主要整理了该论文的主要思想,并结合实际的工程硬件实现给出作者的见解:Kim, J., Pugsley, S. H., Gratz, P. V., Reddy, A. N., Wilkerson, C., & Chishti, Z. (2016, October). Path confidence based lookahead prefetching. In 2016 49th Annual IEEE/ACM International Symposium on Microarchitecture (MICRO) (pp. 1-12). IEEE.
基于signature的路径硬件预取算法(SPP),是一种基于压缩的访存地址跨步(stride)信息学习并进行预取的算法。其具有以下的主要特点:
1. 基于压缩的访存地址历史信息来预测复杂的地址模式
2. 跟踪跨物理页的复杂访存地址模式并复用已学习的信息来继续进行预取
3. 引入“信心”来动态调整每条预取路径的预取深度
引言
SPP将访存地址历史存储为压缩形式,最多可以将4个3-bit的访存偏移量(delta)压缩到12-bit的signature当中
该signature可以被用于检测跨两个不同物理页的历史信息
在预取至物理页的边界时可以跨过边界继续进行预取
SPP基于“信心”作为阈值来指导路径预取
“信心”的计算基于先前的delta历史、预取准确度以及预取的深度
SPP仅基于访存的物理地址进行学习
提出本算法的动机以及先前已有的工作
硬件预取需要考虑复杂的访存模式
先前的硬件预取算法没有考虑到局部访存地址模式中不同的delta值组成的历史序列,因此在复杂但可学习/预测的访存地址序列中仅有较低的预取准确度。
硬件预取需要自适应的预取阈值
基于向前(lookahead)的路径预取算法有可能会产生无限循环,必须要限制预取的深度。先前的硬件预取算法仅存在全局以及静态的预取深度限制。预取的深度必须要自适应于当前数据流的预测信心值。
硬件预取与跨物理页边界处理
先前的硬件预取算法难以处理跨越物理页边界的情况(即已经学习的数据流无法继承到另一个物理页当中)。一个高效的硬件预取器必须能够适应跨物理页数据流的预取情景,而不是当进入另一个物理页时要重头开始学习。
SPP微架构/算法设计
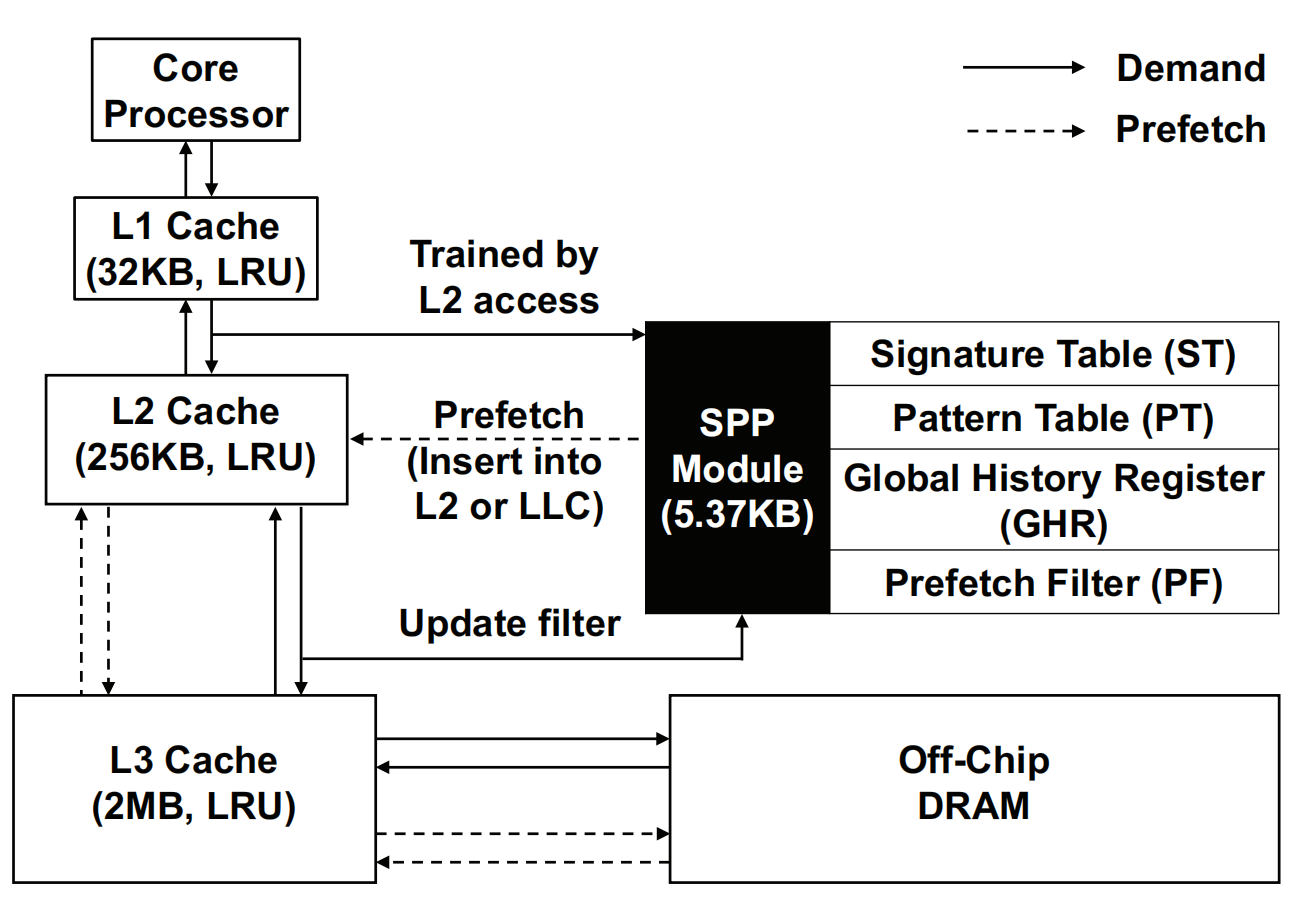
SPP的整体微架构如下图所示:
Signature Table(ST):跟踪最近访问过的物理页,并使用压缩的12-bit的signature来存储该页访存地址模式。
Pattern Table(PT):使用访问ST表得到的signature进行索引,并存储对应signature的若干个预测的访存delta值。
Prefetch Filter(PF):用于检查冗余的预取请求。
Global History Register(GHR):存储跨页的预取请求以加速对跨页预取场景的学习场景。
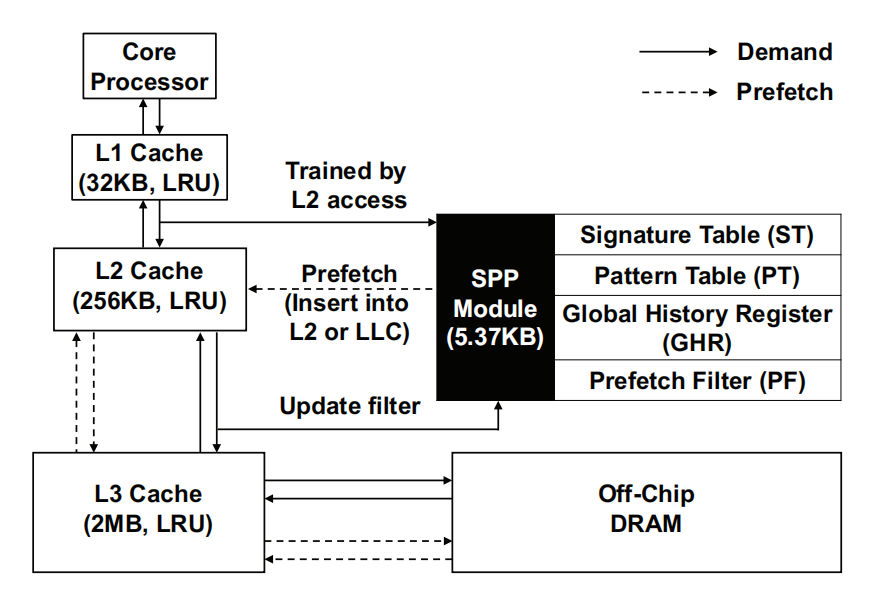
Signature Table
Tag域中存储的是最近使用的物理页的地址以及该页最近访问的offset值(用于计算当前该页访存地址的delta值),以及该页的signature。
当进行访存操作时,同时以当前访存物理页的地址访问ST:
如果命中,则使用当前命中entry的signature去访问PT
否则,则为当前的物理页在ST中分配一个新的entry(分配策略可以是当有空entry时分配空entry,没有则random)
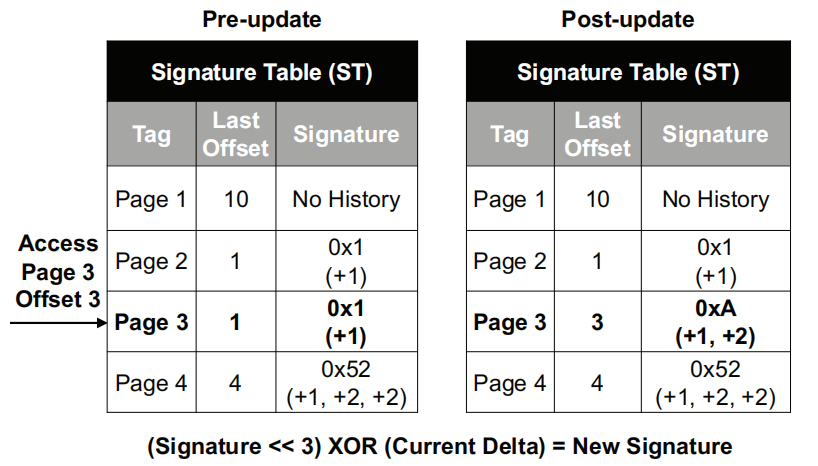
每次访问ST时,如果命中了则根据当前的delta值来更新signature,其公式如下所示:
值得注意的是,假设目前的物理页的大小为4K,且一个cache line的大小为64Byte,则完整的delta需要使用7-bit来表示,这里实际上是将delta值压缩进去signature当中。
Pattern Table
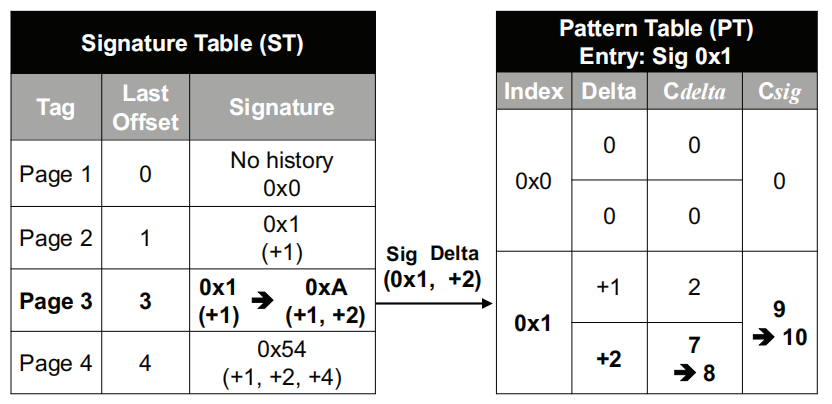
使用访问ST时得到的signature来进行索引(如果没有命中就直接中止不再进行往下的prefetch流程)
由512个entry组成,每个entry存储至多4对
Delta以及C_{delta}对Delta:7-bit,表示当前物理页访问的偏移delta值,用于给出预测的prefetch delta值(基于当前miss的pa或path prefetch的pa)C_{delta}:4-bit,记录该delta值得命中次数,每次访问命中时+1,当饱和了则整个entry所有的计数值右移一位(C_{delta}以及C_{sig})
C_{sig}:4-bit,记录当前entry命中的总次数,每次命中时+1,当饱和了则整个entry所有的计数值右移一位。
当访问PT时索引的entry没有命中任何的pair时,选择最低C_{delta}的pair进行替换。
Global History Register
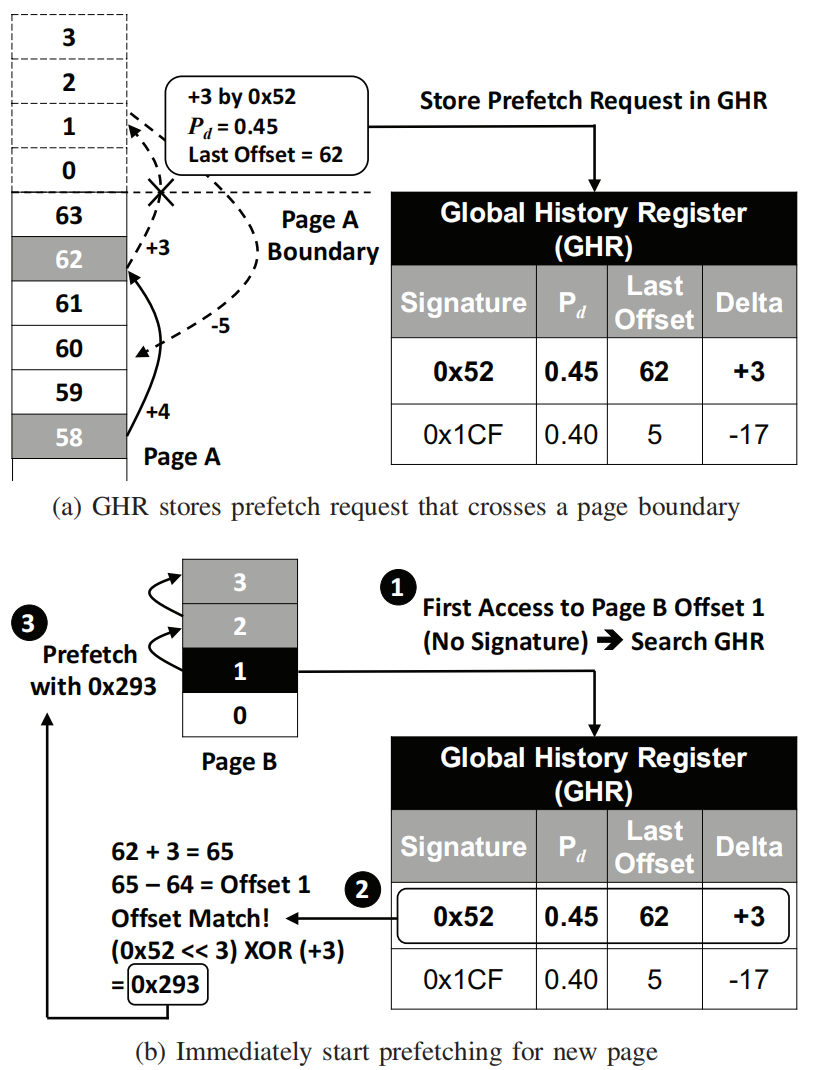
为了降低跨物理页的学习成本(SPP可以基于纯物理地址进行学习,因此需要处理跨物理页的场景),记录所有跨物理页边界的预取请求。
8个entry组成,每个entry记录有signature、path confidence、last offset以及delta。
当一个预取请求需要跨物理页时,首先去查找GHR:
如果命中了一个signature且delta值也相同,则重用该entry的path confidence
如果没有命中,则分配一个新的entry
Prefetch Filter
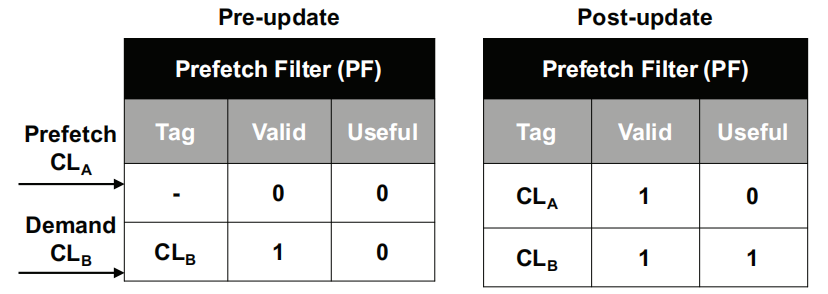
1024个entry组成,记录预取请求的cache line
useful bit用于帮助SPP全局有效预取计数器C_{useful}进行跟踪
SPP预取流程
SPP预取的核心时path confidence。选择某个预取的delta值的confidence可以用下面的公式计算:
其中,选择该delta值的概率是所有选择先前delta值得概率的乘积(也就是整个path prefetch路径的概率乘积):
当发生一次cache miss(作为L1 prefetcher)或者cache access(作为L2 prefetcher)的时候,物理页号以及页内的偏移量将会查找ST。如果命中了,则命中的signature则用于索引PT。如果PT命中,则该命中delta的信心取最高的(预取概率值)C_d为:
则当前PT给出的delta值得path confidence为:
其中\alpha是一个全局的准确率缩放因子,其值可以是静态的,也可以根据当前SPP的全局有效预取请求计数器C_{useful}以及全局总的预取请求计数器C_{total}动态调整(如两者相除得到的值)。
如果P_d比当前预取的阈值T_p要更高,则SPP会issue基于当前delta值计算得到的预取物理地址。此外,一个更高的阈值T_f用于决定预取回来哪一级的cache(L1、L2、LLC)。
在真实的硬件实现当中,不可能使用真正的除法器来计算path confidence,论文中使用了该方法来近似得到:使用一个7-bit的定点数1~100来表示path confidence。而C_{sig}以及C_{delta}由于是4-bit的计数器,则可以使用一个4x4的查找表来得到对应的confidence值。当然,一个整型的乘法器还是不可或缺的。
除了当低信心值会停止预取以外,其他的一些条件可以限制预取,如L2当前处理L1请求的资源不足时。
如果一个预取的访问跨了物理页的边界,SPP会查找GHR来看是否有可重用的信心值。
若当前issue了一笔预取,则SPP还需要查找PF来看这笔预取的cache line是否冗余,如果冗余的话则停止该预取请求发送出去。
最后给出paper原文的各项参数配置供参考:
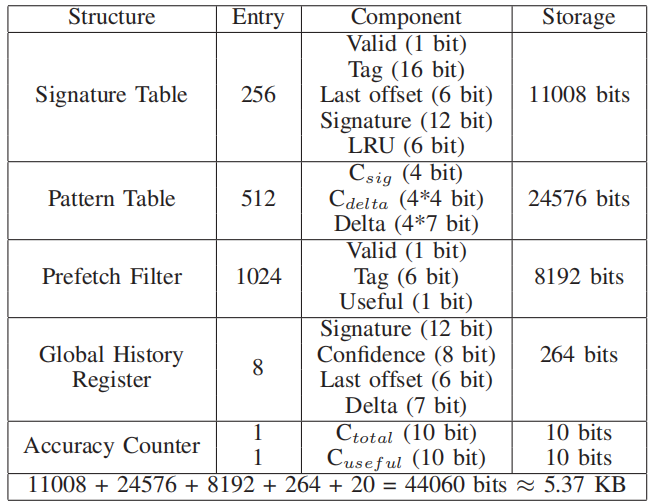
真实硬件实现中的SPP
GHR的作用?
由于SPP可以做到基于纯PA下的运作,因此它无论是作为L1还是L2的硬件预取器都是有效的。如果在L2中实现SPP,则GHR可以得到发挥,因为L2是没有虚拟地址的信息的。然而,如果在L1,也就是LSU中实现SPP的话,实际上可以把GHR去掉,这是因为在LSU中我们是可以得知预取cache line的虚拟地址信息的。当发生跨物理页的情形时,我们可以直接将预测delta值得到的虚拟地址去请求DTLB并得到新的物理地址(当然,如果发生了异常就abort就是了)。
PF的作用?
PF的作用实际上就是一个记录PA tag的prefetch buffer,但是实际上,还有一种办法是,可以使用独立的一个prefetch buffer来代替PF,prefetch buffer的tag使用寄存器搭建,而data则使用SRAM来搭建。这样的好处是可以降低DCache的带宽压力(如果仅记录有限的PA tag,那么每次预取还需要去查一次DCache看是否命中防止预取回来相同的CL),但这里会导致可能会有同样的CL同时存在DCache以及prefetch buffer的情况,这样会增加一致性以及color bit的维护复杂度。当然,如果在L2实现一个相当大的prefetch buffer,那就只能记录PA tag了,data的大小实在是太大了。
path confidence的计算
原文中提到了一种优化path confidence避免使用除法器的办法,实际上这里还有一种转换方式,假设T_p=0.25,其中num以及den分别表示分子以及分母:
这样就可以转换为使用整数的乘法器连乘以及比较器来完成confidence计算了,在1个cycle之类使用DW库来实现的话timing还是可以接受的,因为乘法器的位数也不算多。