SonicBoom Front-end Highlights
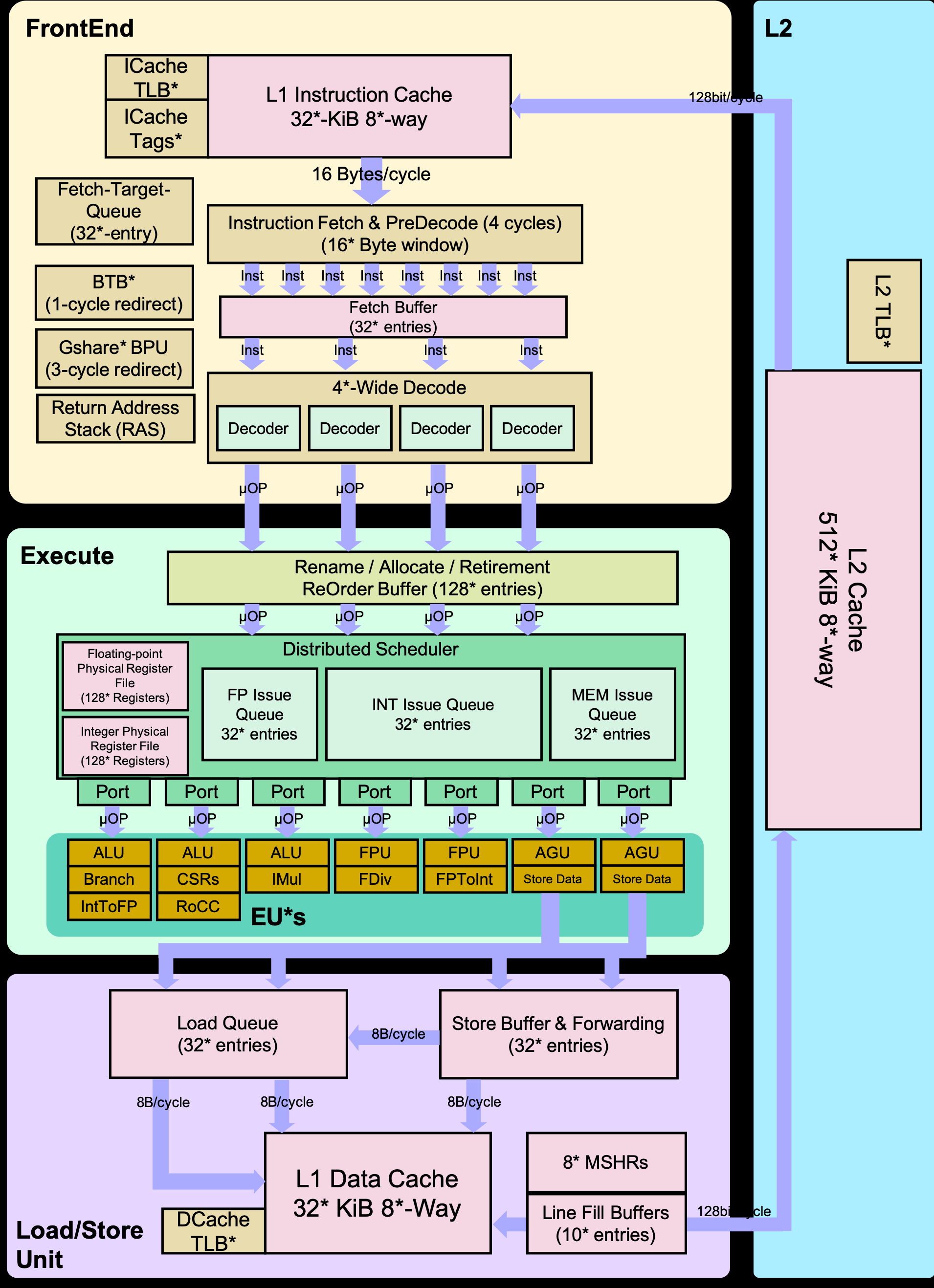
- ICache: 32K 8-way VIPT
- Fetch Width = 8 * 16 = 128-bit (L2 resp width = 128-bit)
- 2-level BTB
- FauBTB (Fully Associative BTB): 0-cycle delay, 16-way, built by register bank
- BTB (L1-BTB/Main BTB): 1-cycle delay, 128-set, 2-way, 8-slot per set, built by SRAM
- BIM: 2048-set, directly map, 8-slot per set, for storing 2-bit ctr information
- eBTB: extended BTB, 128-set, directly map, for storing full target address (VA)
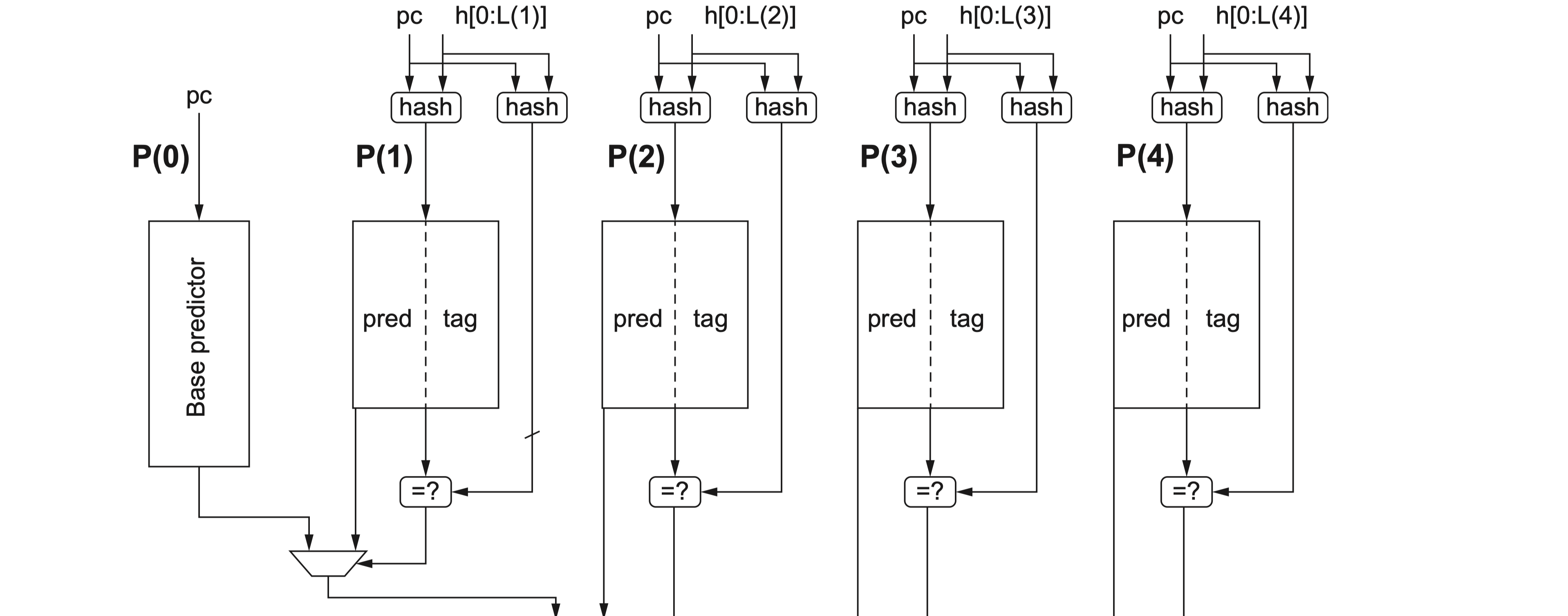
- TAGE-L main predictor
- TAGE: T1 – T6 (Don’t found T0), 3-bit ctr + 2-bit useful design, periodly reset, write bypass supported
- Loop Predictor: 16-sets, built by register bank
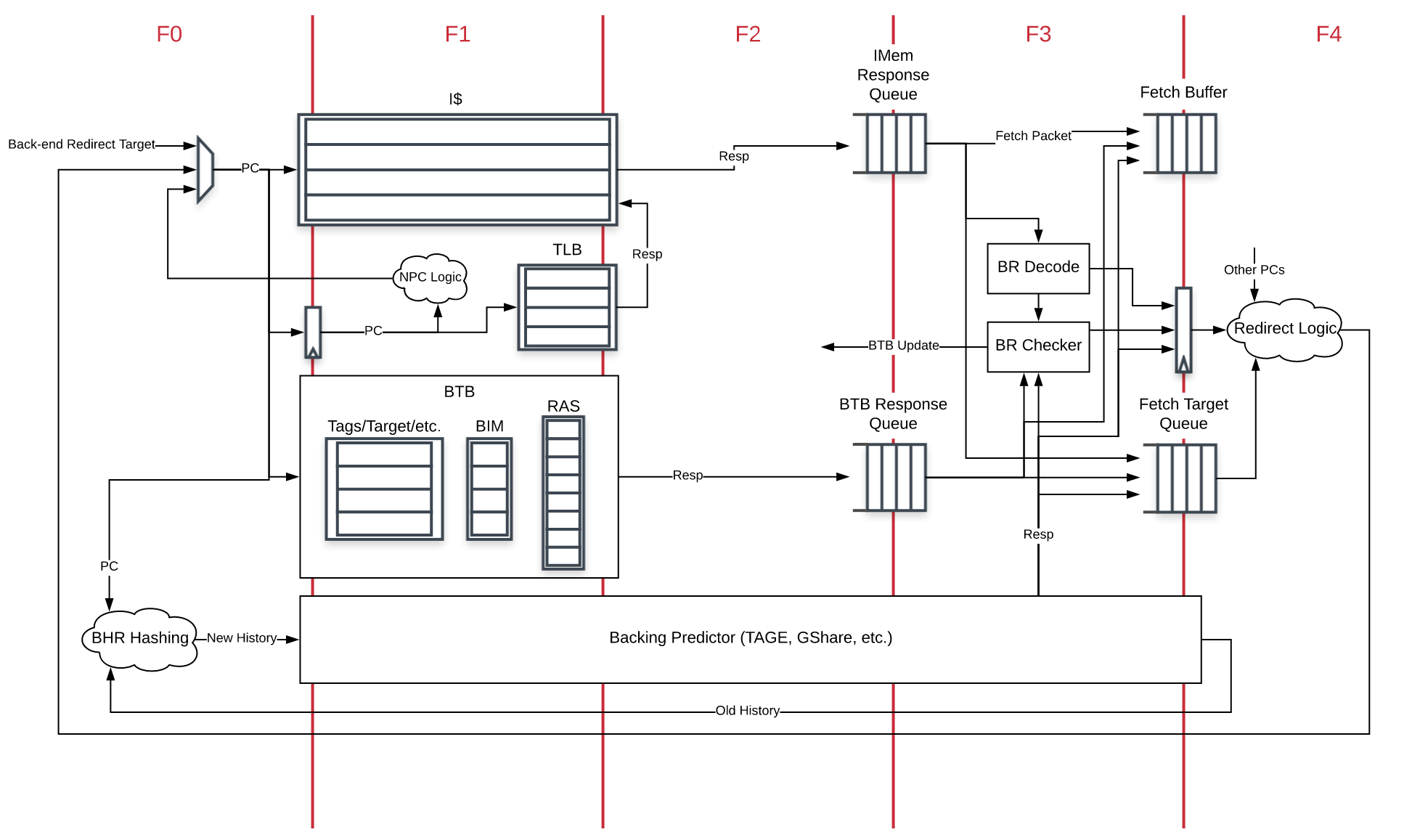
SonicBOOM前端取指为4个cycle:
- F0:
- Next PC Mux Select
- Request L1-BTB
- F1:
- Access ICache/ITLB (VIPT ICache)
- Access FauBTB, get F1 resp
- Access TAGE
- L1-BTB SRAM resp
- F2:
- ICache resp
- L1-BTB output F2 resp
- TAGE resp
- F3:
- Access Loop Predictor (Register Bank)
- GE-L resp
- st. pre-decode
- check (direct jump check/update BTB)
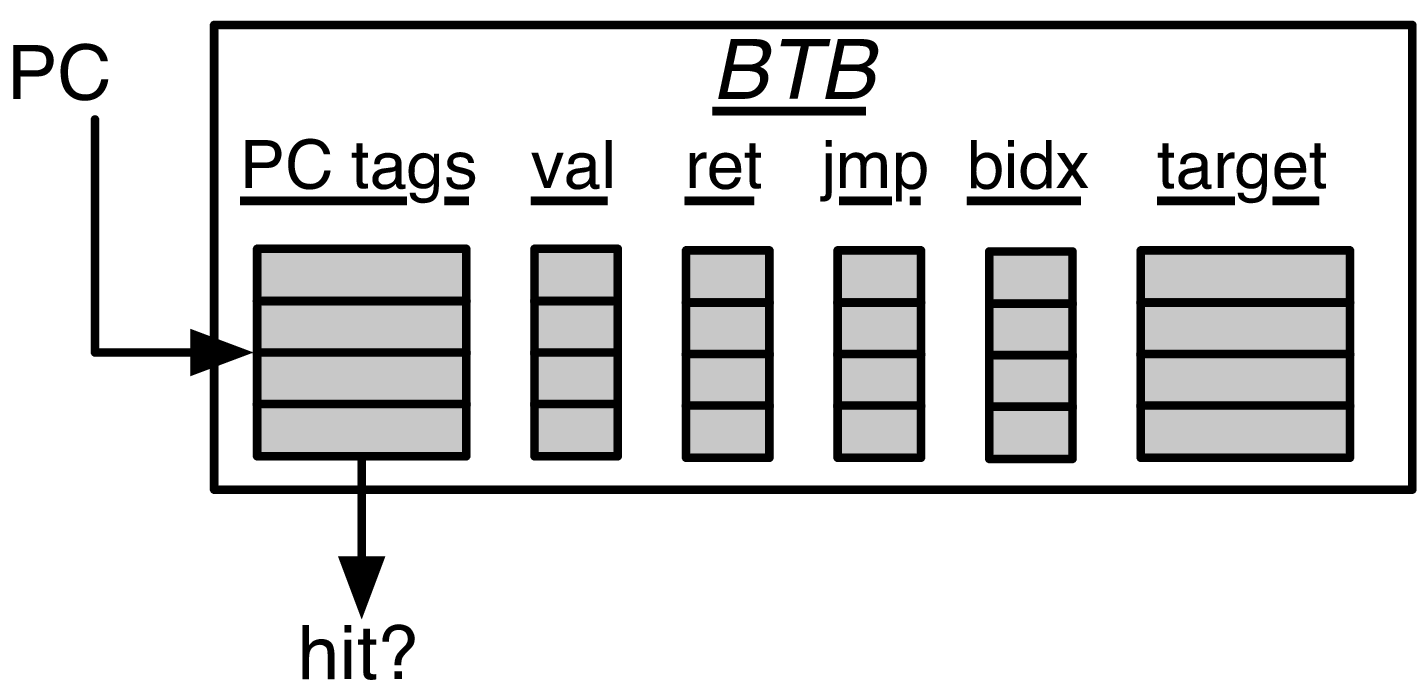
BTB timing
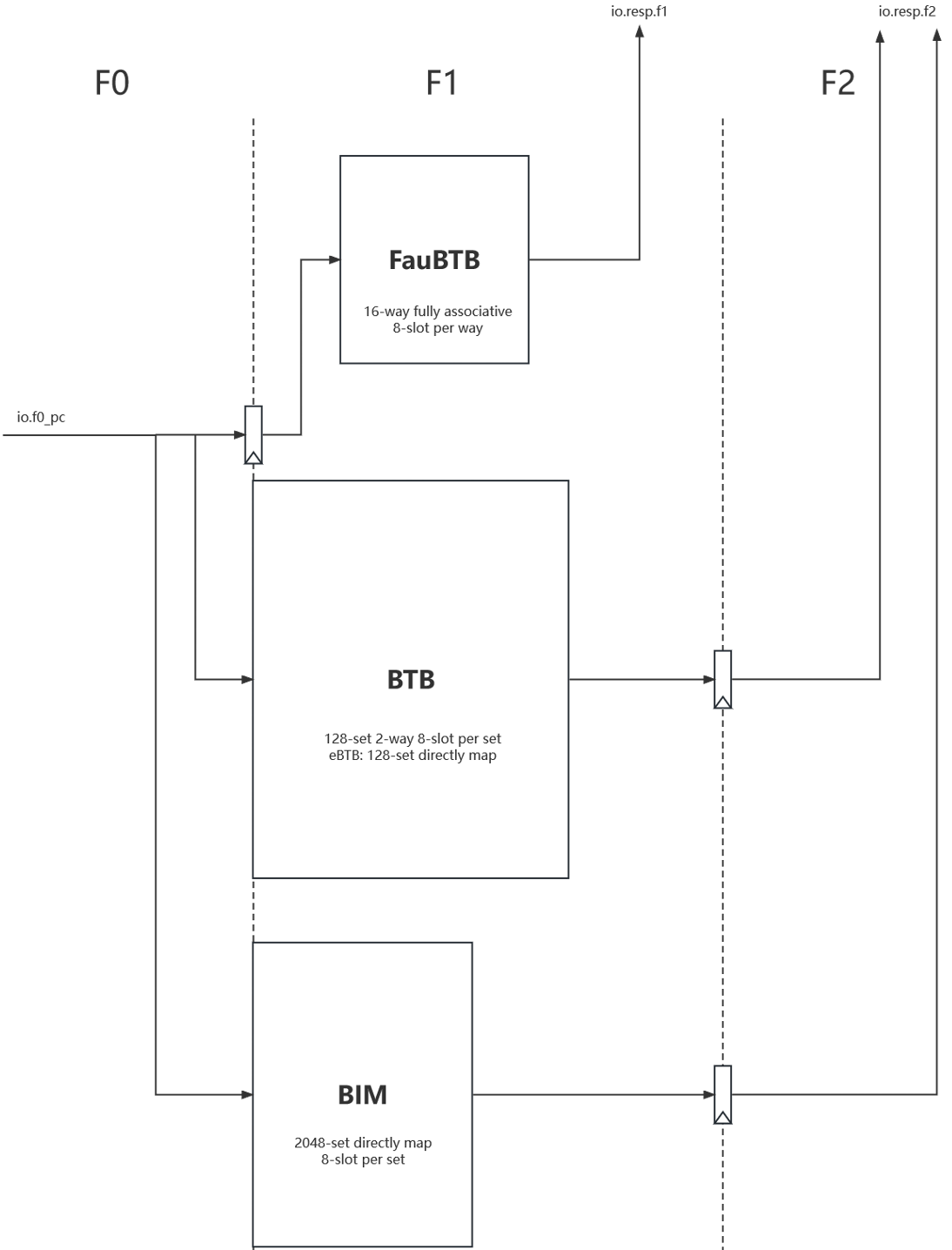
- F0:
- Next PC Mux Select
- Latch F0 PC
- Request L1-BTB (include BIM)
- F1:
- Access FauBTB, get F1 resp
- L1-BTB SRAM resp
- Latch L1-BTB resp
- F2:
- F2 resp from latched F1 resp of L1-BTB
FauBTB

- Fully Associative 16-way
- Register bank
- 8-slot per way (Fetch Width)
- 分开存储offset以及[tag/ctr/br]信息
- offset用于计算next-PC
- tag直接使用PC低位(没有hash)
- is_br用于标记是否是分支指令
FauBTB access
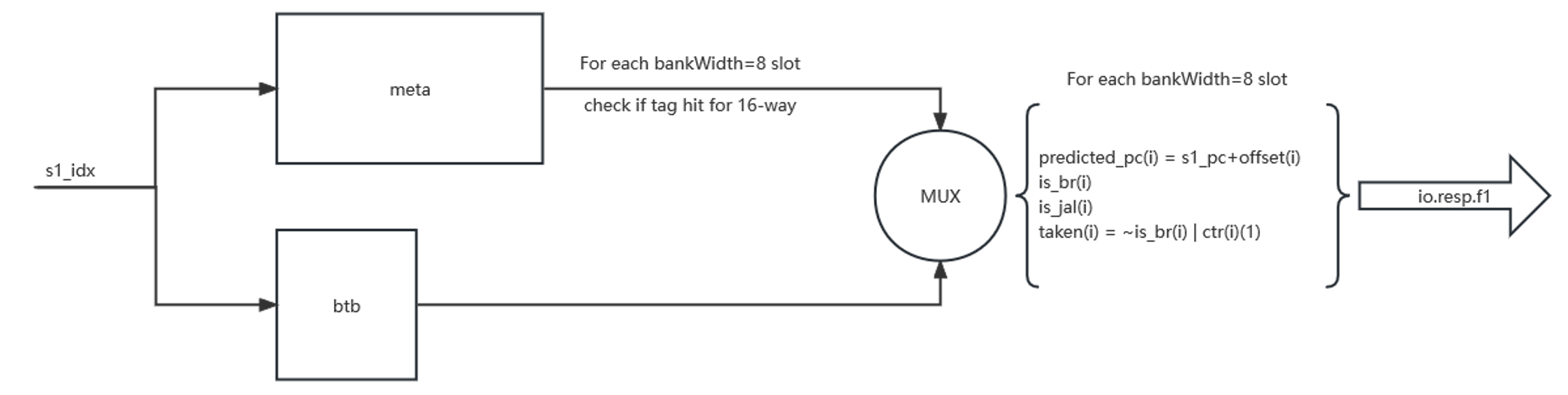
- 对于8个slot,并行比较16个way的tag信息,若命中则:
- 对于每个slot,io.resp.f1输出其[predicted_pc/is_br/is_jal/taken]信息
- 在Front-End层会对F1 resp进行检查,若8个slot存在valid的结果,则将最小命中的slot的结果作为F1 redirect的结果
FauBTB update
Allocate algorithm
flatten_tag = {meta[15][7].tag, meta[15][6].tag, ..., meta[0][0].tag, s1_idx[tagSz-1:0]};
ft_width = getWidth(faltten_tag);
alloc_way = flatten_tag[ft_width-1:ft_width-4] ^ flatten_tag[ft_width-5:ft_width-8] ^ ... ^ flatten_tag[3:0]; // chunk length = log2(16)
- Update信息的来源有两种:
- FTQ的更新信息(优先级最高)
- F3阶段,对指令pre-decode后得到的直接跳转地址,若与BTB的结果不符合则打一排在F4更新
- FauBTB-btb更新:当对应slot是cfi指令且taken时,仅更新所需要way对应的slot的offset值(没有对overflow做处理)
- FauBTB-meta更新:除了update btb对应的slot外,在taken的slot前的br也需要更新(若FG有br,但没有taken,则这些br也都要更新)
- 更新ctr,taken +1; not-taken -1;
Main-BTB
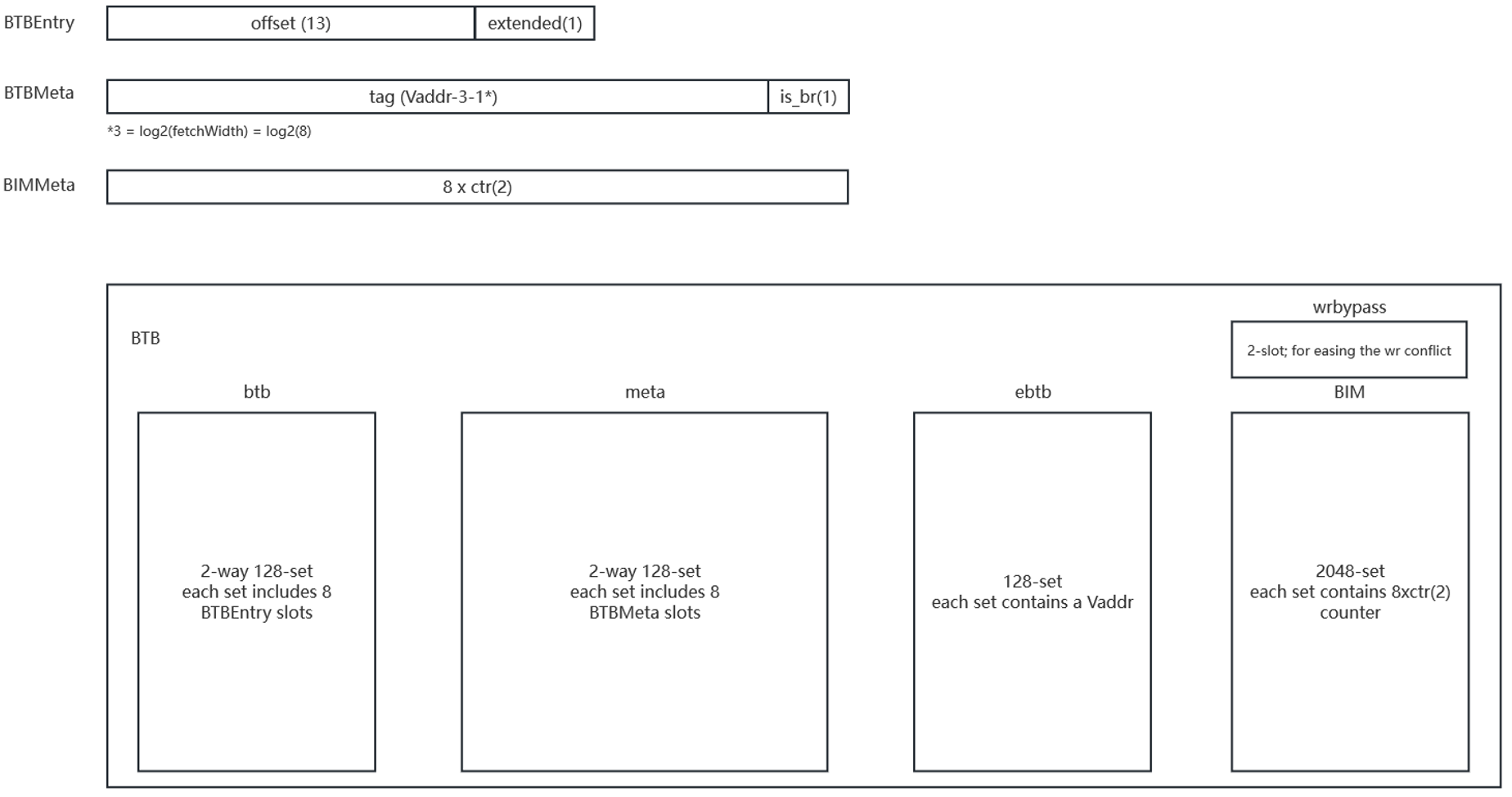
- 基本结构与FauBTB类似,offset以及meta信息分开存放,但ctr使用一个单独的BIM SRAM来存放,且带有write bypass机制
- ebtb用于存放完整的target PC
- 推测BIM兼顾了T0的作用;且BOOM的main predictor没有ijr预测,也是由BTB来兼任
Main-BTB access
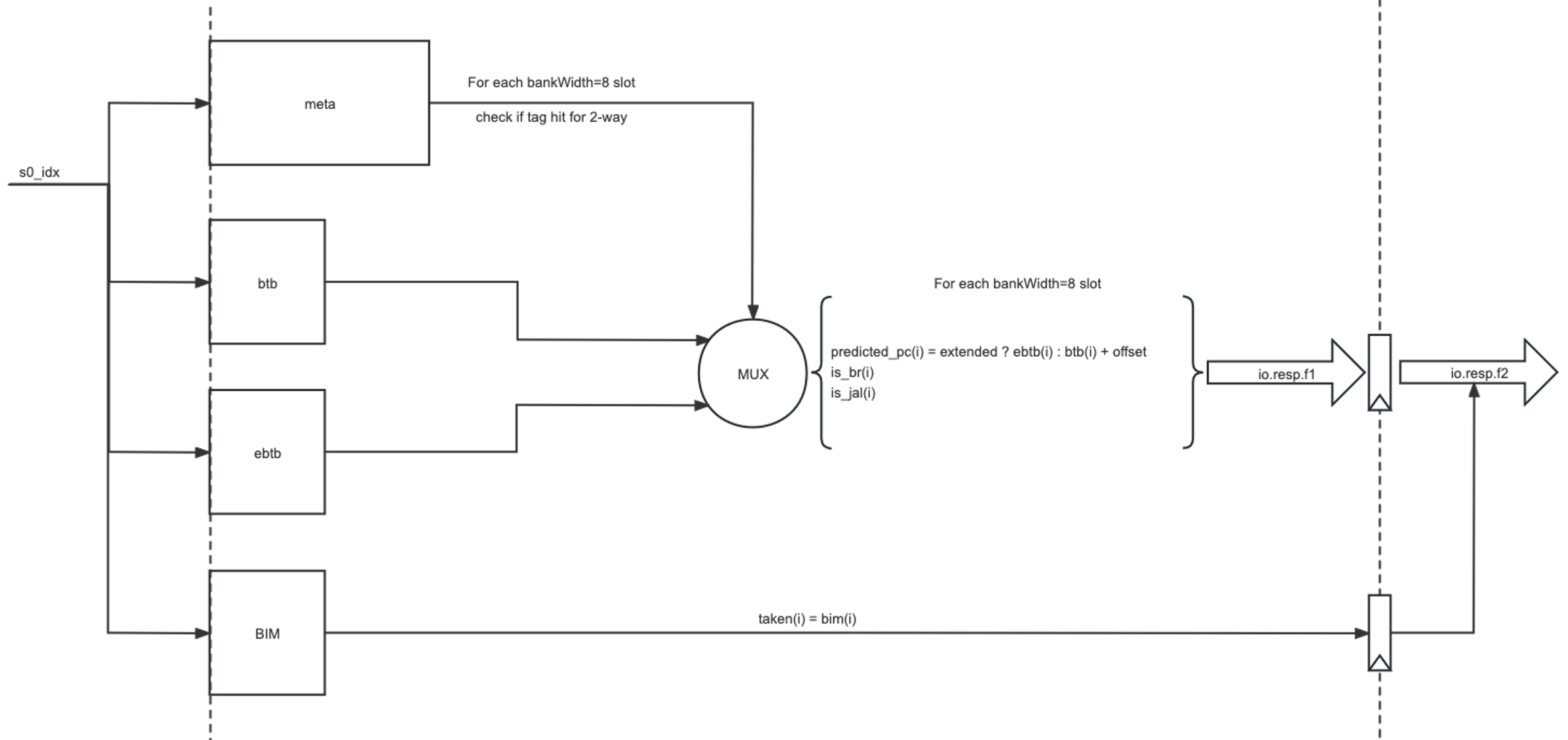
- Allocate算法与FauBTB一致
- Update信息的来源与FauBTB一致
- 且BTB/meta更新的逻辑与FauBTB也一致
- eBTB更新取决于target PC是否overflow offset,如果overflow就放到eBTB中,且BTB对应项标记为extended(对应的BTB entry也会更新)
- BIM更新也与FauBTB的ctr更新逻辑一致
Main-BTB SRAM & write bypass
- BIM中实现有两个entry的write bypass结构,与xiangshan的TAGE wrbypass功能一致(xiangshan的要大得多),也就是当读写冲突时,读优先,然后将写的信息暂存在这个wrbypass当中。下次更新时,查看是否hit wrbypass,若hit则从wrbypass中更新ctr值写入。
- 但BOOM并没有做读写冲突的处理,而是直接用chisel built-in SyncReadMem来实现SRAM
- 双端口SRAM?- timing/area过不去,且wrbypass没用
- 单端口SRAM?- 推测是,但无法确定,原因见下
- BOOM (chipyard) 的SRAM mapping flow: